LLM Wiki vs. Baza Wiedzy RAG
Czy wzorzec projektowy Andreja Karpathy’ego jest naprawdę rewolucyjny?
 Piotr Chlebek · 2026-4-15
Piotr Chlebek · 2026-4-15
Streszczenie: Artykuł analizuje innowacyjny wzorzec projektowy „LLM Wiki” Andreja Karpathy’ego, stanowiący alternatywę dla klasycznych systemów RAG. Autor opisuje proces aktywnej kompilacji surowych danych w trwałą bazę Markdown, która pozwala na autonomiczną kumulację i syntezę wiedzy. Tekst wnikliwie zestawia korzyści nowej architektury z wyzwaniami operacyjnymi, wskazując jednocześnie na szeroki wachlarz jej potencjalnych zastosowań.
Słowa kluczowe: LLM Wiki, Andrej Karpathy, RAG (Retrieval-Augmented Generation), Baza wiedzy AI, Destylacja danych, Zarządzanie wiedzą (Knowledge Management), Kompilacja wiedzy, Markdown Wiki, Optymalizacja kosztów LLM, Personal Knowledge Base (PKB), Druga pamięć (Second Brain), Semantyczny dryf, Inżynieria RAG, Obsidian AI, Audit wiedzy (Linting).
LLM Wiki vs. RAG
Na początku kwietnia 2026 roku  Andrej Karpathy przedstawił nowy wzorzec projektowy —
LLM Wiki [1].
Jest to schemat budowania osobistych baz wiedzy z wykorzystaniem modeli językowych.
Pomysł wydaje się obiecujący, ponieważ próbuje zaadresować istotne słabości systemów LLM+RAG.
Wprowadza nowe mechanizmy i uzupełnia system o bazę wiedzy, której rozbudowa oraz utrzymanie mogą być w pełni autonomiczne (zarządzane przez LLM), a jednocześnie audytowane przez człowieka.
Rozwiązuje on problem braku kumulacji wiedzy oraz poprawia zdolność do syntezy informacji z wielu źródeł.
Andrej Karpathy przedstawił nowy wzorzec projektowy —
LLM Wiki [1].
Jest to schemat budowania osobistych baz wiedzy z wykorzystaniem modeli językowych.
Pomysł wydaje się obiecujący, ponieważ próbuje zaadresować istotne słabości systemów LLM+RAG.
Wprowadza nowe mechanizmy i uzupełnia system o bazę wiedzy, której rozbudowa oraz utrzymanie mogą być w pełni autonomiczne (zarządzane przez LLM), a jednocześnie audytowane przez człowieka.
Rozwiązuje on problem braku kumulacji wiedzy oraz poprawia zdolność do syntezy informacji z wielu źródeł.
„Idea jest tutaj inna. Zamiast tylko pobierać dane z surowych dokumentów w momencie zadawania pytania, LLM stopniowo buduje i utrzymuje trwałą wiki — uporządkowaną, wzajemnie powiązaną kolekcję plików Markdown, która znajduje się między Tobą a źródłami surowymi”.
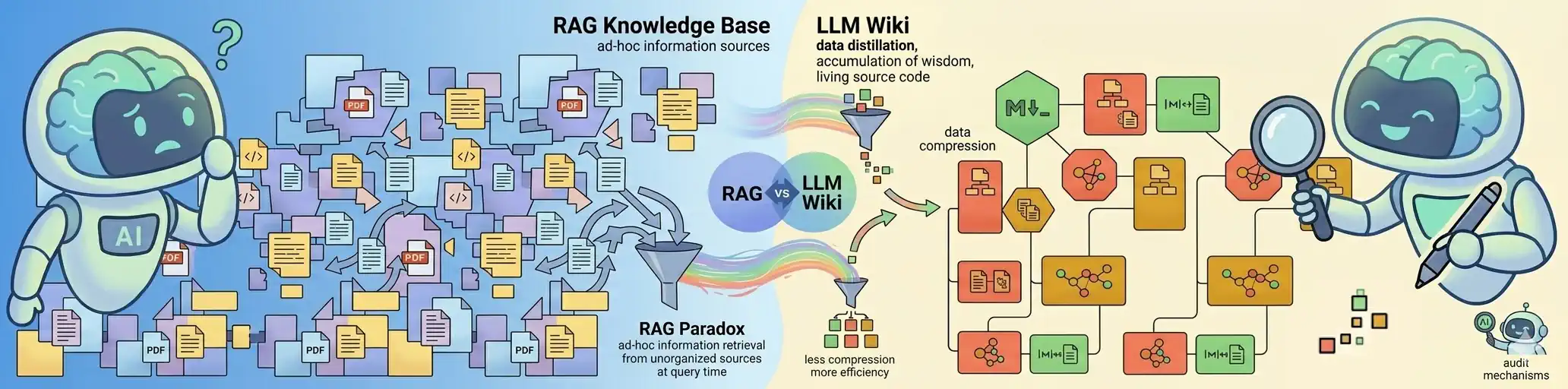
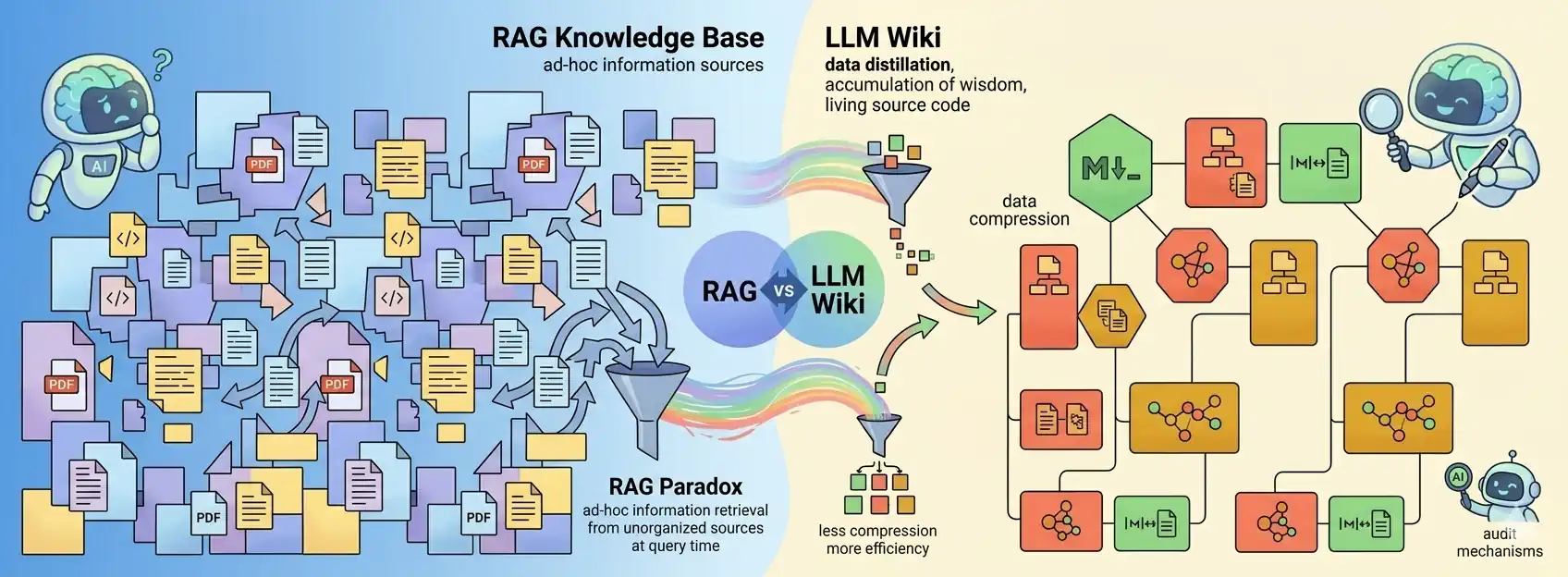
LLM Wiki to system RAG typu „Wiki-First”. Wykorzystuje on mechanizm RAG do przeszukiwania bazy wiedzy, która jest na bieżąco tworzona i aktualizowana przez sam model. Dzięki temu system „uczy się” i z czasem buduje coraz szerszy kontekst, zamiast zaczynać od zera przy każdym nowym zapytaniu.
Koncepcja ta reprezentuje zmianę paradygmatu:
Przejście od wyszukiwania (RAG) do kompilacji surowych dokumentów w spójną, stale aktualizowaną bazę wiedzy.
Traktuje ona wiedzę nie jako statyczną bibliotekę do przeszukiwania, ale jako „żywy kod źródłowy”, który sztuczna inteligencja aktywnie przebudowuje i utrzymuje.
Kluczowe różnice w pigułce
Ponieważ LLM Wiki to wciąż nowość, skupiłem się w tym porównaniu głównie na płaszczyźnie koncepcyjnej. Oczywiście RAG RAG-owi nierówny, a i samo LLM Wiki będzie z czasem ewoluować. Pewne fundamentalne różnice widać jednak jak na dłoni już teraz. Dopiero gdy je dostrzeżemy i zrozumiemy ich realny wpływ oraz ograniczenia, będziemy mogli w pełni świadomie budować rozwiązania najwyższej klasy.
Oto ciekawe zestawienie różnic między LLM Wiki a RAG, oparte na
artykule [2]
autorstwa Emily Winks.
Według autorki:
„Największe różnice ujawniają się na trzech płaszczyznach: skali, infrastruktury i ładu danych. LLM Wiki wygrywają pod względem prostoty i wydajności tokenowej poniżej progu 50 000 – 100 000 tokenów. RAG zwycięża w kategoriach skali, dynamiki i dostępu wieloużytkownikowego. Żadne z nich nie wygrywa w kwestii korporacyjnego ładu danych – to wymaga całkowicie osobnej warstwy”
Podsumowanie najważniejszych punktów:
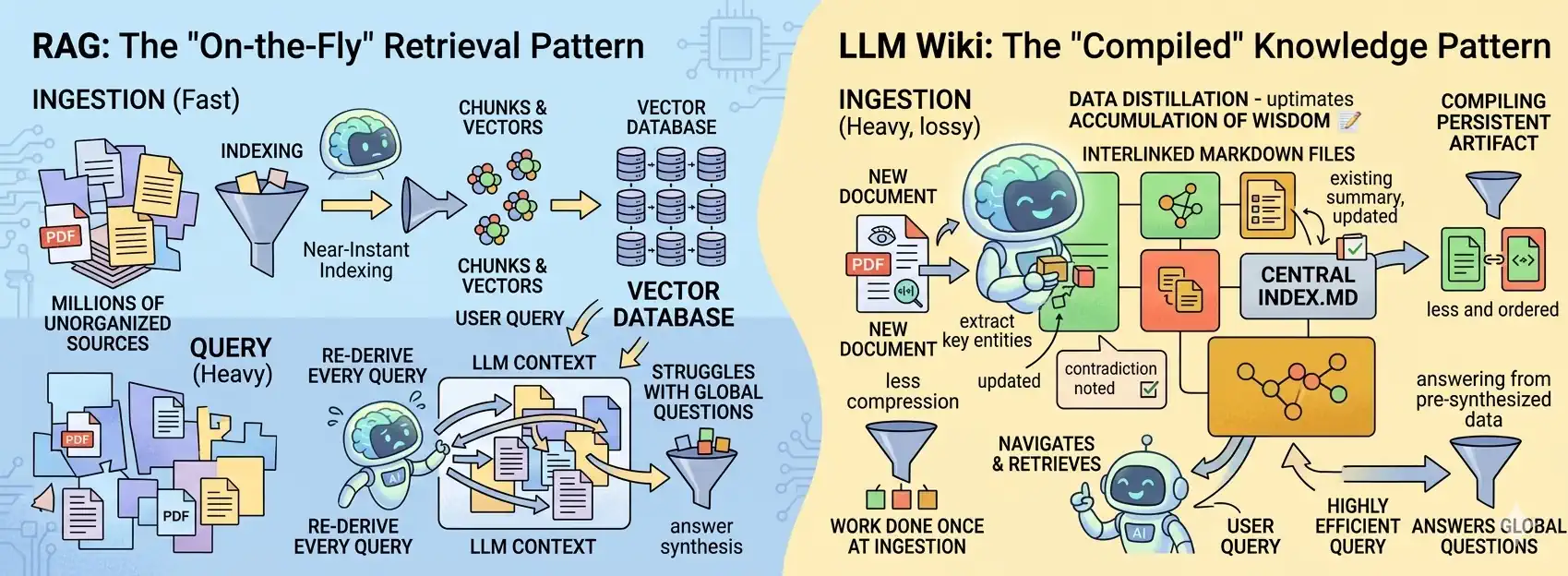
- Architektura: LLM Wiki ładuje do kontekstu cały, uporządkowany indeks. RAG działa inaczej – w momencie zadania pytania dynamicznie „wyciąga” konkretne fragmenty wiedzy z bazy wektorowej.
- Skala: LLM Wiki radzi sobie świetnie w granicach 50–100 tysięcy tokenów. RAG podczas budowy bazy wektorowej nie ma „sufitu” – udźwignie miliony dokumentów.
- Infrastruktura: LLM Wiki to rozwiązanie niemal bezobsługowe – nie potrzebujesz dodatkowego zaplecza. RAG wymaga już całej machinerii: bazy wektorowej, mechanizmów zamiany tekstu na wektory (embeddingów) oraz warstwy wyszukiwania.
- Zarządzanie danymi: Żadne z tych podejść samo w sobie nie rozwiązuje kwestii bezpieczeństwa danych w firmie. Do tego niezbędny jest osobny system, np. profesjonalny katalog danych z zaawansowanym nadzorem dostępu.
Paradoks RAG: Dlaczego odkrywamy koło na nowo?
Obecnie standardem jest RAG (Retrieval-Augmented Generation). Wrzucasz dokumenty, zadajesz pytanie, a AI przeszukuje bazę. Brzmi dobrze? Tylko na pozór. Z RAG-iem wiążą się dziesiątki wyzwań – wymaga on solidnego podejścia inżynieryjnego i silnych fundamentów architektonicznych. Przy każdym zapytaniu system przeszukuje cały zbiór dokumentów (a w zasadzie ich fragmentów), dokonuje selekcji najważniejszych informacji i całą pracę związaną z ich syntezą zaczyna od zera. Oczywiście, identyczne zapytania może obsłużyć cache. Jeśli jednak jutro zapytasz o coś bardzo podobnego, podstawowy RAG ponownie wyciągnie te same fragmenty dokumentów (często całkiem spory stos), ułoży je w nowej kolejności i znów będzie musiało mozolnie składać sens z tej rozsypanki.
Co gorsza, procesowanie odbywa się na ograniczonej liczbie fragmentów tekstu, co oznacza, że zdecydowana większość z nich nie zostanie przeanalizowana podczas budowania odpowiedzi. Choć jest to efekt w pewnym stopniu pożądany – nie chcemy przecież brać pod uwagę treści niezwiązanych z pytaniem – ma on swoje skutki uboczne. Bardzo często zdarza się bowiem, że luźniej powiązane fragmenty, które wciąż są ważne w danym kontekście, zostają po prostu pominięte
LLM Wiki odwraca ten proces. Zamiast szukać informacji dopiero w momencie zadawania pytania (Query-time), kompilujemy wiedzę już w chwili jej dodawania (Ingest-time). AI staje się Twoim osobistym redaktorem, który na bieżąco przepisuje i łączy fakty w spójną całość. Dzięki temu przy każdym zapytaniu nie musimy przeszukiwać wszystkich dokumentów od nowa. Wystarczy, że do kontekstu wstawimy już skompilowaną wiedzę (jeżeli mieści się w oknie kontekstowym) lub jej wyselekcjonowaną, uporządkowaną część (gdy baza jest zbyt obszerna lub limity modelu LLM są zbyt restrykcyjne). W podejściu LLM Wiki, baza wiedzy jest znacznie stabilniejsza. Nawet jeśli zmienisz zapytanie, AI za każdym razem operuje na kompletnym zbiorze informacji, co gwarantuje znacznie wyższą spójność odpowiedzi.
LLM Wiki: Rewolucyja czy tylko efekt „hype’u” Andreja Karpathy’ego?
Zdania są podzielone. Sceptycy krytykują, że to nic nowatorskiego, że rozwiązanie nie ma przyszłości i że się nie skaluje. Optymiści zachwalają te elementy, które funkcjonują lepiej, i roztaczają radosne wizje na temat przyszłości LLM Wiki. Myślę, że jest jeszcze za wcześnie, by to rozstrzygać. Zamiast tego proponuję, abyśmy przyjrzeli się zaletom i wadom tego rozwiązania.
Patrząc na to zagadnienie systemowo, widzę dużą wartość w odseparowaniu bazy wiedzy (czy też grafu wiedzy) od samego LLM i mechanizmu RAG. Mam jednak wątpliwości, czy Wiki jako model organizacji danych sprawdzi się przy dużej skali i czy nie potrzebujemy tu innej abstrakcji. Owszem, format Wiki jest niezwykle przydatny, gdy człowiek audytuje treść lub gdy przenosimy wiedzę do kontekstu promptu.
Jednak zebrana wiedza może spoczywać w strukturach dedykowanych, podczas gdy za jej audyt i zasilanie modelu odpowiadać będzie osobna warstwa narzędziowa.
Takie narzędzia mogą po prostu wyekstrahować dane i skonwertować je do czytelnego formatu Markdown dopiero w momencie, gdy będzie to potrzebne.
Mimo że temat jest stosunkowo świeży, pojawiły się już próby użycia LLM Wiki w połączeniu z grafem wiedzy – zobacz np. wideo [3] od Nodus Labs.
W tym poście:
- LLM Wiki vs. RAG
- LLM Wiki: Rewolucyja czy tylko efekt „hype’u” Andreja Karpathy’ego?
- Potencjał i korzyści płynące z LLM Wiki
- Wyzwania i ograniczenia LLM Wiki
- Zastosowania LLM Wiki
- Podsumowanie starcia: LLM Wiki vs. RAG
Powiązane wpisy:
- AI Tinkerers Gdańsk Meetup – 23 kwietnia
- W RAG nie chodzi o AI, lecz o inżynierię
- Lokalne serwowanie LLM za pomocą vLLM
- Hybrydowy RAG z segmentacją semantyczną
Odniesienia:
- [1] GitHub: karpathy/llm-wiki.md - Andrej Karpathy
- [2] Artykuł: LLM Wiki vs RAG Knowledge Base: The Karpathy Approach Explained - Emily Winks
- [3] YouTube: Fix Karpathy’s LLM Wiki with a Knowledge Graph | Claude Code + Obsidian + InfraNodus - Nodus Labs
Źródło obrazów: Google DALL-E 3 (04.2026).
Potencjał i korzyści płynące z LLM Wiki
Koncepcja LLM Wiki to obietnica, że nasza wiedza przestanie być niemożliwą do przebrnięcia stertą tysięcy linków. Stanie się dynamicznym opisem istotnych zagadnień – pigułką zawierającą kluczowe informacje i relacje między nimi. To miejsce, gdzie jak w soczewce można skupić się na tym, co ważne i wygodnie zarządzać rozproszonymi danymi. Oto co sprawia, że to podejście tak bardzo rozpala umysły:
Przełom w Efektywności i Kosztach
- Ekstremalna kompresja (Destylacja): Obietnica 95% redukcji zużycia danych to finansowa rewolucja.
Zamiast płacić za każdorazowe przesyłanie fragmentów surowych dokumentów do modelu, płacisz tylko raz za ich destylację do skondensowanych, czystych notatek Markdown.
Pozorny wzrost kosztów, spowodowany wrzucaniem do kontekstu całej wiki, można znacząco zmniejszyć, wykorzystując mechanizm buforowania promptów (Prompt Caching).
Jak zauważa sam autor [1]:
[O RAG-u] „LLM odkrywa wiedzę na nowo przy każdym pytaniu. Brak tu efektu kumulacji”
[O LLM Wiki] „Wiedza jest kompilowana raz, a następnie aktualizowana, zamiast być wyprowadzana od zera przy każdym zapytaniu” - Wyższa precyzja odpowiedzi: Skupienie się na „esencji” eliminuje szum informacyjny. Model nie gubi się w długim kontekście (tzw. lost-in-the-middle), co przekłada się na trafniejsze wnioski.
- Błyskawiczny czas odpowiedzi: Mniejszy i czystszy kontekst wejściowy oznacza, że model generuje odpowiedzi znacznie szybciej, zbliżając nas do płynnej interakcji w czasie rzeczywistym.
- Uproszczony stos technologiczny: Przejście z kosztownych baz wektorowych i skomplikowanych serwerów na zwykły system plików sprawia, że system jest tańszy, łatwiejszy w utrzymaniu i odporniejszy na awarie.
Nowa Jakość Wiedzy (AI jako Cyfrowy Bibliotekarz)
- Kumulatywna mądrość: Wiedza w LLM Wiki „puchnie” i dojrzewa organicznie. Wnioski wyciągnięte miesiące temu automatycznie łączą się z nowymi danymi, dzięki czemu system faktycznie staje się mądrzejszy z każdym dodanym plikiem.
- Wykrywanie sprzeczności (Linting): To mechanizm „kompilacji wiedzy”. AI podczas audytu wykrywa konflikty między nowymi faktami a starymi notatkami, zmuszając nas do rozstrzygnięcia, co jest prawdą, a co błędem w rozumowaniu.
- Automatyczna standaryzacja: Niezależnie od tego, czy źródłem jest chaotyczna transkrypcja, czy techniczny PDF, LLM Wiki zamienia wszystko na spójny, ustrukturyzowany format, który jest łatwy do przeszukiwania zarówno dla AI, jak i dla człowieka.
- Wizualizacja „topologii myśli”: Dzięki graficznym widokom powiązań (Graph View) widzisz mapę swojej wiedzy. Pozwala to odkryć nieoczywiste mosty między odległymi dziedzinami, których nie widać w luźnych plikach.
Suwerenność i Bezpieczeństwo Danych
- Prawdziwa własność (Human-Readable): Twoja wiedza to pliki tekstowe na dysku. Nawet jeśli dostawcy AI znikną, Twoja baza zostaje z Tobą – wciąż jest czytelna dla człowieka i dowolnego prostego edytora przez kolejne dekady.
- Prywatność przez lokalność: Możliwość uruchomienia procesów audytu i wyszukiwania całkowicie offline (przez lokalne modele) pozwala na bezpieczne przetwarzanie najbardziej wrażliwych tajemnic firmowych czy intymnych przemyśleń.
- Transparentność i „papierowy ślad”: Każde twierdzenie w Wiki ma bezpośrednie odniesienie do źródłowego pliku w folderze raw/. To drastycznie ogranicza halucynacje i pozwala w sekundę sprawdzić, skąd AI wzięło dany wniosek.
Psychologiczna Ulga i Odciążenie Poznawcze
- Koniec z poczuciem winy (Anty-FOMO): Możesz gromadzić setki ciekawych artykułów bez stresu, że ich nie przeczytałeś. Masz pewność, że AI je „przetrawi” i zaserwuje Ci ich esencję dokładnie wtedy, gdy zapytasz o dany temat.
- Skupienie na tworzeniu, nie na sprzątaniu: AI przejmuje żmudną rolę archiwisty – dba o tagi, formatowanie i linkowanie wewnętrzne. Ty zostajesz architektem, który zajmuje się tylko zadawaniem pytań i łączeniem faktów.
- Realizacja obietnicy „Drugiego Mózgu”: To ostateczne dopełnienie wizji Second Brain. Technologia w końcu usuwa największą barierę, która zniechęcała użytkowników: konieczność ręcznego, mozolnego utrzymywania porządku w notatkach.
Zdaniem entuzjastów to właśnie LLM Wiki wyznacza właściwy kierunek rozwoju osobistych systemów AI. Zamiast budować wielkie i ciężkie „magazyny danych”, stawiamy na precyzyjne „destylarnie wiedzy”. To fundamentalna zmiana paradygmatu: przejście od surowego przetwarzania ilościowego do budowania głębokiego, strukturalnego zrozumienia.
Wyzwania i ograniczenia LLM Wiki
Choć wizja Andreja Karpathy’ego brzmi niezwykle kusząco, jej realizacja wprowadza szereg unikalnych wyzwań oraz ograniczeń technicznych. Skoro LLM przestaje być tylko czytelnikiem, a staje się aktywnym autorem i redaktorem bazy wiedzy, wymagania dotyczące precyzji oraz utrzymania spójności systemu znacznie rosną. Warto więc przeanalizować główne trudności i bariery, jakie niesie ze sobą ten wzorzec:
Architektura i Bariery Skalowania
- Wąskie gardło indeksu: To kluczowy limit – rozrost pliku index.md może przekroczyć okno kontekstowe modelu. Wymusza to tworzenie podindeksów, co niepotrzebnie komplikuje architekturę systemu.
Jak zauważył sam autor [1]:
„Działa to zaskakująco dobrze przy umiarkowanej skali (ok. 100 źródeł, kilkaset stron)…”
- Stratna kompresja (Utrata detali): Podczas destylacji treści do formatu wiki, AI nieuchronnie gubi subtelne detale. Jeśli użytkownik będzie chciał dotrzeć do źródłowego niuansu, system i tak wymusi powrót do surowych plików, co podważa sens pełnej automatyzacji.
- Brak transakcyjności (Race Conditions): Markdown to nie baza danych SQL. Jeśli agent i człowiek (lub dwóch agentów) zaczną edytować ten sam plik jednocześnie, narażamy się na „piekło konfliktów”, utratę danych lub błędy w synchronizacji. To ogromna bariera dla pracy zespołowej.
- Brak natywnego RBAC (uprawnień): W systemie opartym na plikach tekstowych trudno o selektywny dostęp. Agent zazwyczaj musi widzieć wszystko, by budować relacje, co wyklucza trzymanie w jednej bazie danych wrażliwych i ogólnych.
Ekonomia i Wydajność Systemu
- Uzależnienie od modeli „klasy ciężkiej”: LLM Wiki wymaga najwyższej klasy rozumowania (np. najpotężniejszych dostępnych modeli LLM). Próba uruchomienia audytu czy kompilacji na mniejszych, lokalnych modelach zazwyczaj kończy się porażką strukturalną i błędami w linkowaniu.
- Wysoki koszt operacyjny: Przetworzenie jednej nowej informacji wymaga od modelu wielu operacji odczytu i zapisu w różnych plikach. To znacznie droższe i bardziej obciążające dla API niż proste wygenerowanie embeddingu w klasycznym RAG-u.
Zdaniem autora [1]:
„Przetworzenie jednego źródła może wymagać edycji 10-15 stron wiki”.
- „Podatek od kompilacji”: Pierwsza kompilacja dużej bazy (np. 1000 dokumentów) może wygenerować potężny rachunek i trwać godzinami. To inwestycja, która zwraca się w czasie, ale na starcie wymaga dużego budżetu i cierpliwości.
Ryzyko Degradacji i Halucynacji
- Semantyczny dryf (Głuchy telefon): Kiedy AI streszcza streszczenie, z czasem dochodzi do uproszczeń i kumulowania drobnych błędów. Po kilku cyklach aktualizacji, Twoja wiedza może stać się powierzchowną karykaturą oryginału.
- Ślepota na sprzeczności: Jeśli konfliktowa informacja nie znajdzie się w aktualnym oknie kontekstowym podczas audytu, AI może jej nie wyłapać. Prowadzi to do powstania „mętnych” i sprzecznych artykułów, które dla modelu stają się nową prawdą absolutną.
- Halucynacje strukturalne: AI uwielbia „na siłę” łączyć niepowiązane koncepty lub tworzyć błędne linki wewnętrzne. Bez twardej walidacji (lintingu) baza szybko wypełni się logicznymi „potworkami”, które trudno wyłapać.
Bariera utrzymania z udziałem człowieka (Human-in-the-loop)
- Wysoki koszt nadzoru: Ciężar pracy przesuwa się z pisania na żmudne sprawdzanie, czy bot nie „namieszał” w strukturze plików. Bez aktywnego zaangażowania człowieka system szybko zamieni się w cyfrowy strych pełen martwych odnośników.
- „Zmęczenie Promptem”: Stworzenie instrukcji, która rygorystycznie pilnuje formatowania YAML i schematu danych, wymaga wielu testów i ciągłego poprawiania po błędach modelu.
- Zależność od narzędzi trzecich: Budując system wokół specyficznych narzędzi (np. Obsidian + konkretne pluginy), stajesz się ich zakładnikiem. Każda zmiana w sposobie renderowania Markdowna może wymagać bolesnej przebudowy całej architektury.
Zdaniem optymistów LLM Wiki to obecnie najbardziej ambitna próba uporządkowania cyfrowego chaosu. Choć technologia ta wymaga dyscypliny i wysokych kosztów początkowych, oferuje coś, czego nie daje żaden klasyczny RAG: żywą, dojrzewającą strukturę wiedzy zamiast martwego archiwum plików. Ostatecznie sukces tego podejścia zależy od tego, czy zaakceptujemy nową rolę – już nie tylko zbieraczy danych, ale aktywnych redaktorów własnej mądrości.
Zastosowania LLM Wiki
Autor wyróżnia pięć głównych zastosowań dla LLM Wiki [1]:
- Osobiste zarządzanie wiedzą (PKM): Centralizacja różnorodnych danych i refleksji w celu śledzenia długoterminowego rozwoju oraz budowania ustrukturyzowanego, cyfrowego portretu własnego życia.
- Badania i research: Synteza gromadzonych przez długi czas złożonych informacji w celu dopracowania ewoluującej tezy oraz wychwytywania niespójności między źródłami.
- Towarzysz lektury i mediów („Czytanie książki”): Tworzenie dynamicznej, wzajemnie powiązanej wiki, która automatycznie mapuje postacie, motywy i powiązania narracyjne w miarę przyswajania treści przez użytkownika.
- Biznes i zespoły: Utrzymywanie samonaprawiającej się wewnętrznej bazy wiedzy, która przekształca rozproszoną komunikację (Slack, spotkania) w spójny i zawsze aktualny zasób.
- Analiza konkurencji, due diligence, planowanie podróży, notatki z kursów, hobbystyczne zgłębianie tematów: Wszystko, co wiąże się z gromadzeniem wiedzy w czasie i wymaga organizacji zamiast rozproszenia.
Mam wrażenie, że pojawi się jeszcze wiele innych zastosowań LLM Wiki. Mogę sobie wyobrazić mnóstwo przypadków, w których aktywna synteza informacji sprawdzi się idealnie – szczególnie w sytuacjach, gdy ilość dokumentów (wiedzy) jest stosunkowo mała. Przykładowo:
- POC chatbota lub voicebota: Wiele firm, które po raz pierwszy wdrażają chatbota lub voicebota, nie posiada dużej bazy wiedzy. Zapisanie posiadanych informacji w postaci wiki to „dar z niebios” dla kogoś, kto stawia pierwsze kroki. Dzięki temu luźne i nieustrukturyzowane dokumenty zostają skonwertowane do postaci zarządzalnej i użytecznej. Przegląd (review) oraz wersjonowanie tej bazy są wyjątkowo ważne podczas wdrażania kolejnych iteracji projektu (POC).
- Notatki głosowe: Trudno oczekiwać, aby zbiór notatek głosowych posiadał głębszą strukturę. Owszem, nagranie ma datę, a skrupulatny użytkownik może przypisać mu temat czy tagi. Mimo to, w miarę jak notatek przybywa, coraz trudniej odnaleźć relacje między informacjami czy konkretne szczegóły wykraczające poza proste etykiety. Zastosowanie LLM Wiki daje nadzieję, że notatki te będzie można nie tylko łatwiej przeszukiwać, ale i analizować, a wszelkie sprzeczności i niespójności – sprawnie namierzyć i rozwiązać.
- Narracja i tworzenie światów (World-building) dla twórców: Pisarze i Mistrzowie Gry często zmagają się z problemem „rozmycia spójności” (continuity drift). Jeśli piszesz powieść lub prowadzisz złożoną kampanię D&D, LLM może zadbać o to, by odwołanie do przeszłości bohatera w późniejszym rozdziale automatycznie wywołało flagę sprzeczności z rozdziałem początkowym, w którym ta przeszłość została opisana inaczej. System pełni tu rolę Redaktora Spójności.
- Mapowanie długu technicznego i dokumentacji: Kody źródłowe zmieniają się szybciej niż dokumentacja. Karmiąc LLM Wiki commitami z Gita i opisami Pull Requestów, można utrzymać wysokopoziomową wiki „Architektury Systemu”. Wypełnia to lukę między surowym kodem (Źródła) a zrozumieniem dewelopera (Wiki), odnotowując miejsca, w których nowe funkcje mogą kolidować z logiką legacy.
- Zarządzanie sprawami prawnymi lub medycznymi: Dziedziny te wiążą się z ogromną ilością „Surowych Źródeł” (dokumentacja medyczna, akta sądowe), gdzie synteza danych jest kluczowa. LLM Wiki mogłoby prowadzić „Główną Oś Czasu” lub „Podsumowanie Dowodów”, aktualizowane wraz z dodawaniem nowych dokumentów. Funkcja lintingu (kontroli poprawności) byłaby tu nieoceniona przy wykrywaniu sprzecznych zeznań lub luk w historii choroby.
- Rejestr kariery i marki osobistej: Ludzie z biegiem lat zapominają o własnych osiągnięciach. Przetwarzając oceny okresowe, retrospektywy projektów i e-maile, LLM buduje ustrukturyzowaną wiki Twoich umiejętności i sukcesów opisanych metodą S.T.A.R. (Sytuacja, Zadanie, Akcja, Wynik). Kiedy przychodzi czas na aktualizację CV lub rozmowę o pracę, cała synteza jest już gotowa.
Podsumowanie starcia: LLM Wiki vs. RAG
W 2026 roku RAG stał się wyjątkowo użyteczny, powszechny i zoptymalizowany. Jest dostarczany w wielu różnych odmianach („smakach”), a jego ekosystem stale rośnie. RAG jest stosowany produkcyjnie w tysiącach projektów; wiele jego cech jest nam już dobrze znanych. Znamy też jego ograniczenia oraz problemy, na które opracowaliśmy skuteczne rozwiązania mitygujące.
LLM Wiki (w przeciwieństwie do klasycznego RAG) jest nowością. Wzorzec ten wykorzystuje mechanizm RAG „pod spodem”, jednak robi to w nieco inny sposób. Z podejściem tym wiążą się spore nadzieje i niewątpliwie, w miarę rozwoju, LLM Wiki może stać się ciekawą alternatywą. LLM Wiki to odpowiednie narzędzie dla średniej wielkości kontekstów wymagających wysokiej precyzji, gdzie synteza wiedzy jest ważniejsza niż rozmiar bazy danych. Może być jednak znacznie mniej efektywne w scenariuszach, w których RAG zdecydowanie dominuje.
Myślę, że jest jeszcze za wcześnie, aby przenosić do LLM Wiki systemy produkcyjne oparte na RAG. Warto natomiast przeprowadzić eksperymenty, by sprawdzić, w jakim stopniu ten nowy wzorzec nadaje się do konkretnego problemu lub domeny. Dotyczy to zwłaszcza sytuacji, gdy mamy do czynienia z bardzo małą liczbą dokumentów w bazie wiedzy. Warto trzymać rękę na pulsie, bo mam wrażenie, że czeka nas interesujący rozwój tej idei, a nowe rozwiązania podobne do LLM Wiki mogą okazać się jeszcze bardziej rewolucyjne i przydatne.