Lokalne serwowanie LLM za pomocą vLLM
Budowa efektywnej kosztowo infrastruktury AI: Lokalne serwowanie LLM przez vLLM
 Piotr Chlebek · 2026-4-(praca w toku)
Piotr Chlebek · 2026-4-(praca w toku)
Streszczenie: in progress..
Słowa kluczowe: in progress..
(praca w toku)
Jak obsłużyć 5,46 miliona promptów LLM bez „podatku od API”
Problem 5 milionów promptów
W ramach projektu Hybrydowy RAG z segmentacją semantyczną zmierzyłem się z ogromnym wyzwaniem: analizą 780 000 stron dokumentów. Moim celem było wykorzystanie LLM do ekstrakcji metadanych, które usprawniłyby wyszukiwanie informacji. Matematyka była nieubłagana — przy kilku promptach na każdą stronę, projekt urósł do skali 5 milionów zapytań do modelu LLM.
Dlaczego vLLM?
W moim przypadku najważniejszym parametrem jest przepustowość (czyli ile zadań kończy się w ciągu godziny), a nie opóźnienie (jak szybko pojedyncze zadanie zostaje ukończone). Po zapoznaniu się z opiniami w internecie, postanowiłem wypróbować vLLM.
Warto wspomnieć, że istnieje wiele innych silników do serwowania modeli — kilka z nich wymieniłem obok tego artykułu. Choć ich porównanie wykracza poza ramy tego projektu, byłby to świetny temat na przyszły artykuł.
Sprzęt
Optymalizacja
Modele
Monitorowanie
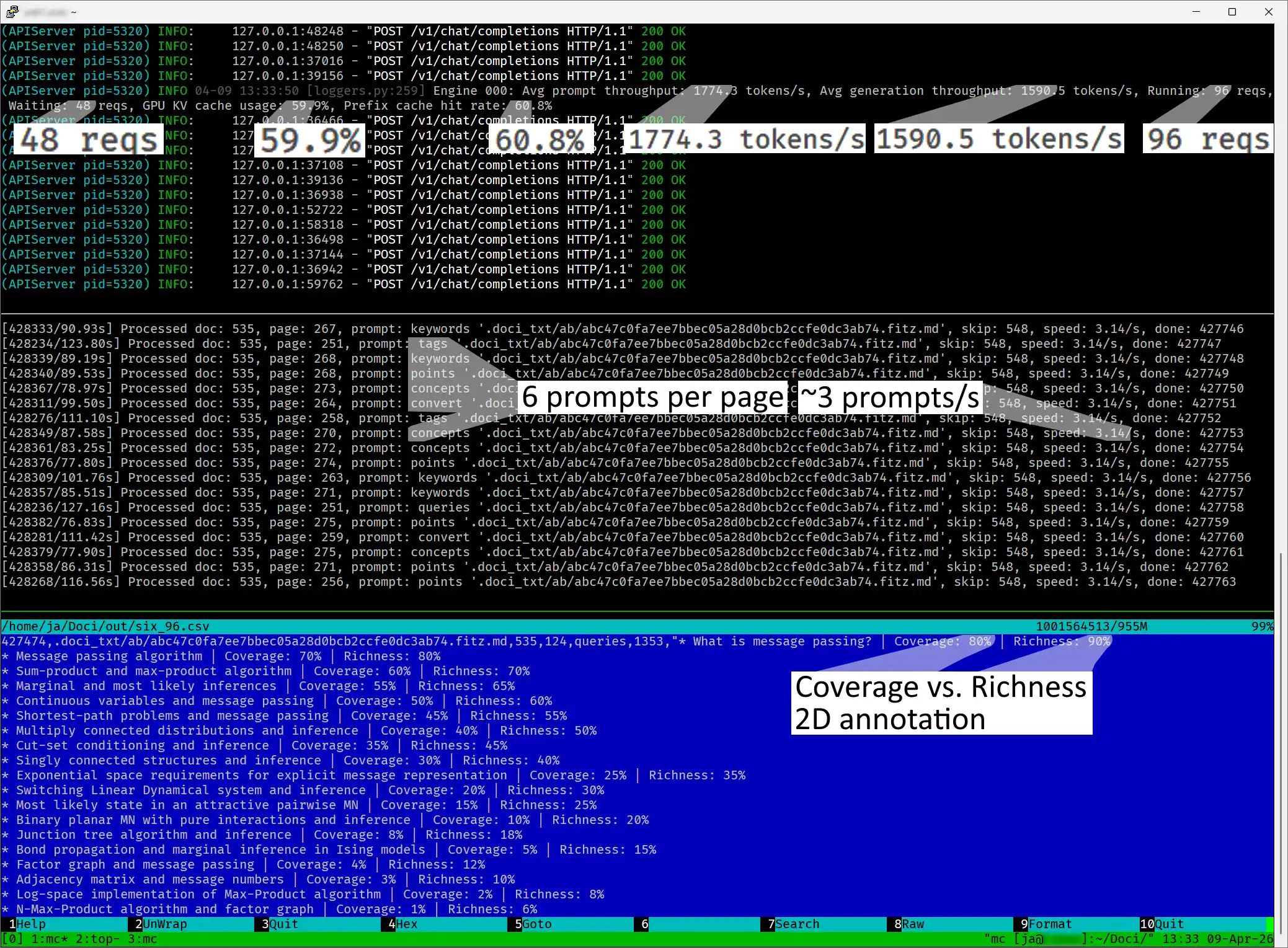
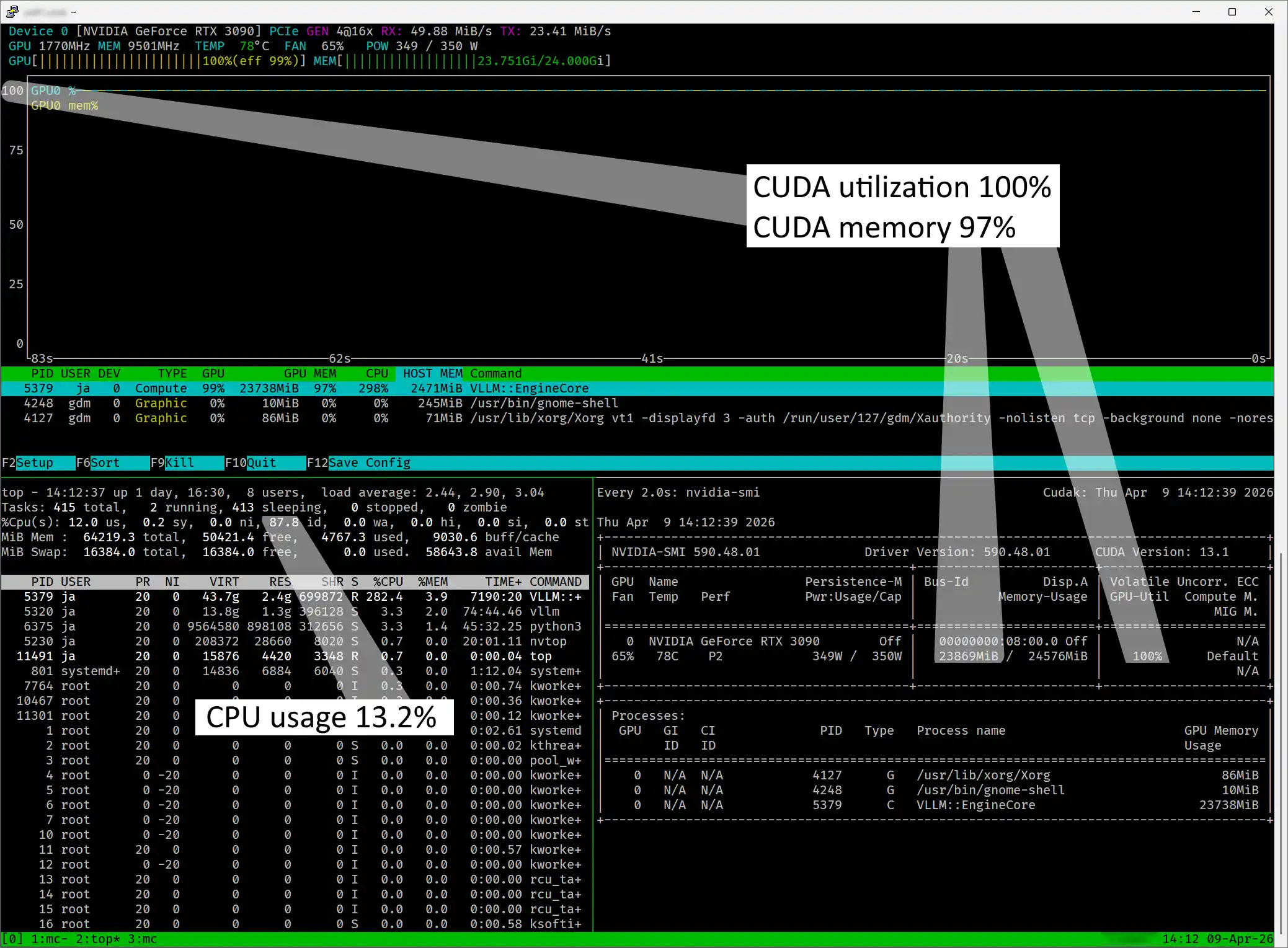
Wnioski
...W tym poście:
- (praca w toku)
Powiązane wpisy:
- AI Tinkerers Gdańsk Meetup – 23 kwietnia
- W RAG nie chodzi o AI, lecz o inżynierię
- LLM Wiki vs. Baza Wiedzy RAG
- Hybrydowy RAG z segmentacją semantyczną
Opcje serwowania LLM
- vLLM – silnik o wysokiej przepustowości, zaprojektowany dla maksymalnej wydajności pamięci.
- NVIDIA Triton – wybór klasy korporacyjnej, stworzony do skalowania o wysokiej wydajności.
- SGLang – szybki framework do serwowania modeli językowych i multimodalnych.
- LMDeploy – wyspecjalizowany zestaw narzędzi do kompresji i wdrażania wydajnych modeli.
- TensorRT-LLM – oficjalna biblioteka NVIDIA do najnowocześniejszych optymalizacji GPU.
- TGI – zestaw narzędzi od Hugging Face do niezawodnego wdrażania LLM w środowisku produkcyjnym.
- Ollama – najprostszy i najpopularniejszy sposób na lokalne uruchamianie otwartych modeli.
- LM Studio – przyjazna dla użytkownika aplikacja desktopowa do prywatnych, lokalnych eksperymentów z AI.
- LocalAI – kompletna, lokalna alternatywa dla popularnych rozwiązań chmurowych AI API.
- Ray Serve – elastyczny system do budowania skalowalnych i programowalnych usług AI.
- llama.cpp – lekki fundament w C/C++ do szybkiej inferencji na dowolnym sprzęcie.
Odniesienia:
- (praca w toku)
Źródło obrazów: Google DALL-E 3 (04.2026).