LLM-Wiki vs. RAG-Wissensdatenbank
Ist Andrej Karpathys Design-Pattern wirklich revolutionär?
 Piotr Chlebek · 2026-4-15
Piotr Chlebek · 2026-4-15
Zusammenfassung: Der Artikel analysiert Andrej Karpathys innovatives Designmuster „LLM Wiki“, das eine Alternative zu klassischen RAG-Systemen darstellt. Der Autor beschreibt den Prozess der aktiven Kompilierung von Rohdaten in eine beständige Markdown-Wissensdatenbank, die eine autonome Akkumulation und Synthese von Wissen ermöglicht. Der Text stellt die Vorteile der neuen Architektur den operativen Herausforderungen fundiert gegenüber und zeigt zugleich ein breites Spektrum an Anwendungsmöglichkeiten auf.
Schlüsselwörter: LLM Wiki, Andrej Karpathy, RAG (Retrieval-Augmented Generation), KI-Wissensdatenbank, Datendestillation, Wissensmanagement, Wissenskompilierung, Markdown-Wiki, LLM-Kostenoptimierung, Persönliche Wissensdatenbank (PKB), Second Brain, Semantischer Drift, RAG-Engineering, Obsidian KI, Wissensprüfung (Linting).
LLM Wiki vs. RAG
Anfang April 2026 stellte  Andrej Karpathy ein neues Design-Pattern vor —
LLM Wiki [1].
Dabei handelt es sich um ein Schema zum Aufbau persönlicher Wissensdatenbanken unter Nutzung von Sprachmodellen.
Die Idee erscheint vielversprechend, da sie versucht, wesentliche Schwachstellen von LLM+RAG-Systemen zu adressieren.
Sie führt neue Mechanismen ein und ergänzt das System um eine Wissensbasis, deren Ausbau und Pflege vollständig autonom (durch das LLM gesteuert) erfolgen kann, während sie gleichzeitig für den Menschen prüfbar bleibt.
Das Konzept löst das Problem der fehlenden Wissenskumulation und verbessert die Fähigkeit zur Synthese von Informationen aus mehreren Quellen.
Andrej Karpathy ein neues Design-Pattern vor —
LLM Wiki [1].
Dabei handelt es sich um ein Schema zum Aufbau persönlicher Wissensdatenbanken unter Nutzung von Sprachmodellen.
Die Idee erscheint vielversprechend, da sie versucht, wesentliche Schwachstellen von LLM+RAG-Systemen zu adressieren.
Sie führt neue Mechanismen ein und ergänzt das System um eine Wissensbasis, deren Ausbau und Pflege vollständig autonom (durch das LLM gesteuert) erfolgen kann, während sie gleichzeitig für den Menschen prüfbar bleibt.
Das Konzept löst das Problem der fehlenden Wissenskumulation und verbessert die Fähigkeit zur Synthese von Informationen aus mehreren Quellen.
„Die Idee ist hier eine andere. Anstatt nur Daten aus Rohdokumenten zum Zeitpunkt der Fragestellung abzurufen, baut das LLM schrittweise ein dauerhaftes Wiki auf und pflegt es – eine geordnete, miteinander verknüpfte Sammlung von Markdown-Dateien, die zwischen Ihnen und den Rohquellen steht.“
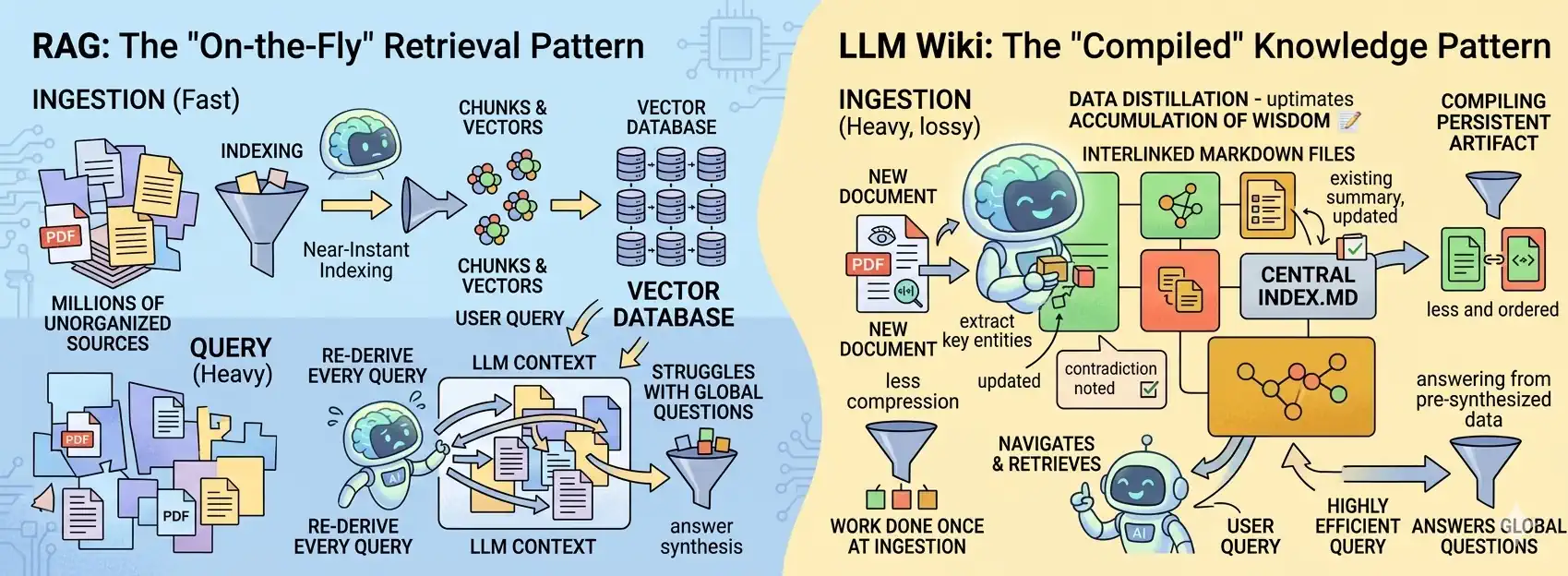
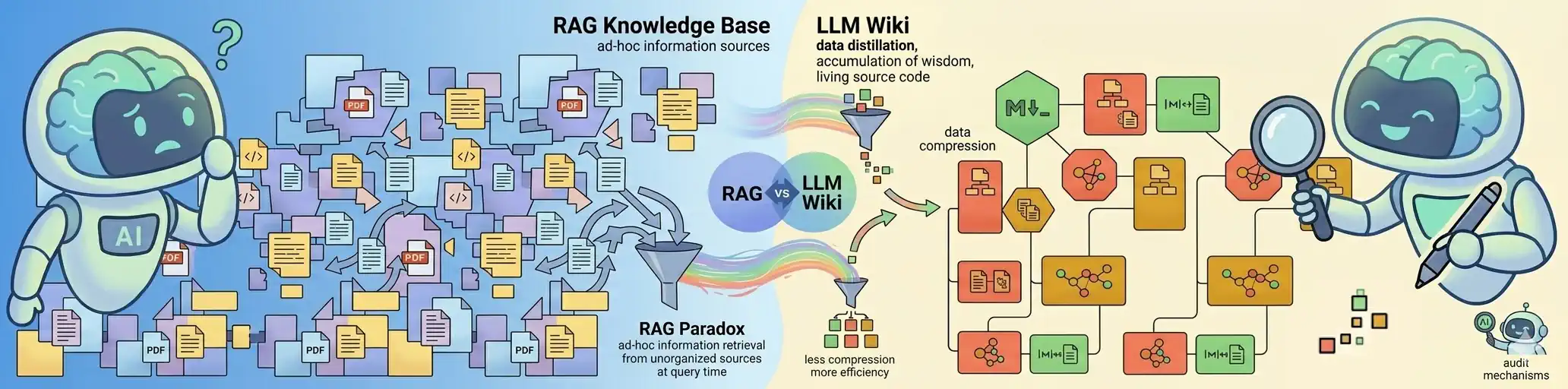
LLM Wiki ist ein RAG-System vom Typ „Wiki-First“. Es nutzt den RAG-Mechanismus, um eine Wissensdatenbank zu durchsuchen, die laufend vom Modell selbst erstellt und aktualisiert wird. Dadurch „lernt“ das System und baut mit der Zeit einen immer umfassenderen Kontext auf, anstatt bei jeder neuen Anfrage bei Null anzufangen.
Dieses Konzept stellt einen Paradigmenwechsel dar:
Der Übergang vom bloßen Suchen (RAG) hin zur Kompilation von Rohdokumenten in eine konsistente, ständig aktualisierte Wissensbasis.
Wissen wird hierbei nicht als statische Bibliothek zum Durchsuchen betrachtet, sondern als „lebendiger Quellcode“, den die KI aktiv umbaut und instand hält.
Die wichtigsten Unterschiede auf einen Blick
Da LLM Wiki noch eine Neuheit ist, habe ich mich in diesem Vergleich hauptsächlich auf die konzeptionelle Ebene konzentriert. Natürlich ist RAG nicht gleich RAG, und auch LLM Wiki selbst wird sich mit der Zeit weiterentwickeln. Bestimmte fundamentale Unterschiede liegen jedoch schon jetzt klar auf der Hand. Erst wenn wir diese erkennen und ihren tatsächlichen Einfluss sowie die damit verbundenen Grenzen verstehen, können wir mit vollem Bewusstsein Lösungen der Spitzenklasse entwickeln.
Hier ist eine interessante Gegenüberstellung der Unterschiede zwischen LLM Wiki und RAG, basierend auf
Artikel [2]
von Emily Winks.
Laut der Autorin:
„Die deutlichsten Unterschiede zeigen sich in drei Bereichen: Skalierung, Infrastruktur und Governance. LLM-Wikis punkten bei Einfachheit und Token-Effizienz unterhalb der Schwelle von 50.000 bis 100.000 Token. RAG überzeugt bei Skalierung, Dynamik und Mehrbenutzerzugriff. Keines von beiden gewinnt in Bezug auf Enterprise-Data-Governance – dies erfordert eine völlig separate Ebene.“
Zusammenfassung der wichtigsten Punkte:
- Architektur: LLM Wiki lädt den gesamten, strukturierten Index in den Kontext. RAG funktioniert anders – im Moment der Fragestellung werden dynamisch spezifische Wissensfragmente aus einer Vektordatenbank „gezogen“.
- Skalierung: LLM Wiki schlägt sich hervorragend im Bereich von 50.000–100.000 Token. RAG hingegen kennt beim Aufbau der Vektordatenbank kein „Limit“ – es bewältigt Millionen von Dokumenten.
- Infrastruktur: LLM Wiki ist eine nahezu wartungsfreie Lösung – es wird kein zusätzliches Backend benötigt. RAG erfordert einen kompletten technischen Apparat: Vektordatenbank, Embedding-Mechanismen und eine Retrieval-Ebene.
- Datenmanagement: Keiner dieser Ansätze löst für sich allein die Frage der Datensicherheit im Unternehmen. Dafür ist ein separates System erforderlich, etwa ein professioneller Datenkatalog mit fortgeschrittener Zugriffskontrolle.
Das RAG-Paradoxon: Warum das Rad neu erfinden?
Derzeit ist RAG (Retrieval-Augmented Generation) der Standard. Man füttert Dokumente ein, stellt eine Frage und die KI durchsucht die Basis. Klingt gut? Nur oberflächlich. RAG bringt dutzende Herausforderungen mit sich – es erfordert einen soliden Engineering-Ansatz und starke architektonische Fundamente. Bei jeder Anfrage durchsucht das System den gesamten Dokumentenbestand (bzw. Fragmente davon), wählt die wichtigsten Informationen aus und beginnt die gesamte Arbeit der Synthese wieder bei Null. Natürlich können identische Abfragen vom Cache bedient werden. Fragt man jedoch morgen nach etwas sehr Ähnlichem, wird das Basis-RAG wieder dieselben Textausschnitte (oft einen beträchtlichen Stapel) ausgeben, sie neu ordnen und muss wieder mühsam den Sinn aus diesem Durcheinander zusammensetzen.
Erschwerend kommt hinzu, dass die Verarbeitung auf einer begrenzten Anzahl von Textfragmenten basiert, was bedeutet, dass der Großteil der Inhalte bei der Erstellung der Antwort gar nicht analysiert wird. Obwohl dies bis zu einem gewissen Grad gewollt ist – man möchte schließlich keine irrelevanten Inhalte berücksichtigen – hat es Nebenwirkungen. Oft passiert es nämlich, dass schwächer verknüpfte Fragmente, die im jeweiligen Kontext dennoch wichtig wären, schlichtweg übergangen werden.
LLM Wiki kehrt diesen Prozess um. Anstatt Informationen erst zum Zeitpunkt der Anfrage (Query-Time) zu suchen, kompilieren wir das Wissen bereits beim Hinzufügen (Ingest-Time). Die KI wird zu Ihrem persönlichen Redakteur, der Fakten laufend umschreibt und zu einem stimmigen Ganzen verbindet. Dadurch müssen wir bei einer Anfrage nicht alle Dokumente von vorne durchsuchen. Es genügt, das bereits kompilierte Wissen in den Kontext einzufügen (sofern es in das Kontextfenster passt) oder einen ausgewählten, geordneten Teil davon (falls die Basis zu umfangreich oder die Limits des LLM zu restriktiv sind). Beim LLM-Wiki-Ansatz ist die Wissensbasis deutlich stabiler. Selbst wenn sich die Abfrage ändert, arbeitet die KI jedes Mal mit dem vollständigen Informationsstand, was eine wesentlich höhere Konsistenz der Antworten garantiert.
LLM Wiki: Revolution oder nur der „Hype“-Effekt von Andrej Karpathy?
Die Meinungen gehen auseinander. Skeptiker kritisieren, dass dies nichts Neues sei, die Lösung keine Zukunft habe und nicht skaliere. Optimisten loben die Elemente, die besser funktionieren, und entwerfen freudige Visionen über die Zukunft von LLM Wiki. Ich denke, es ist noch zu früh für ein abschließendes Urteil. Stattdessen schlage ich vor, die Vor- und Nachteile dieser Lösung genauer zu betrachten.
Systemisch betrachtet sehe ich einen großen Wert darin, die Wissensbasis (oder den Knowledge Graph) vom LLM und dem RAG-Mechanismus selbst zu trennen. Ich habe jedoch Zweifel, ob sich ein Wiki als Datenorganisationsmodell bei großer Skalierung bewährt oder ob wir hier eine andere Abstraktion benötigen. Sicherlich ist das Wiki-Format extrem nützlich, wenn ein Mensch den Inhalt prüft oder wenn wir Wissen in den Kontext eines Prompts übertragen.
Das gesammelte Wissen könnte jedoch in dedizierten Strukturen liegen, während eine separate Werkzeugebene (Tool-Layer) für die Prüfung und die Speisung des Modells verantwortlich ist.
Solche Werkzeuge könnten die Daten einfach extrahieren und erst in dem Moment in ein lesbares Markdown-Format konvertieren, wenn es tatsächlich benötigt wird.
Obwohl das Thema relativ frisch ist, gibt es bereits Versuche, LLM Wiki in Kombination mit einem Knowledge Graph einzusetzen – siehe dazu beispielsweise das Video [3] von Nodus Labs.
In diesem Beitrag:
- LLM Wiki vs. RAG
- LLM Wiki: Revolution oder nur der „Hype“-Effekt von Andrej Karpathy?
- Potenzial und Vorteile von LLM Wiki
- Herausforderungen und Grenzen von LLM Wiki
- LLM Wiki Anwendungsfälle
- Zusammenfassung des Duells: LLM-Wiki vs. RAG
Ähnliche Beiträge:
- AI Tinkerers Gdańsk Meetup – 23. April
- Bei RAG geht es nicht um KI, sondern um Engineering
- Lokales Serving des LLM mit vLLM
- Hybrider RAG mit semantischem Chunking
Referenzen:
- [1] GitHub: karpathy/llm-wiki.md - Andrej Karpathy
- [2] Artikel: LLM Wiki vs RAG Knowledge Base: The Karpathy Approach Explained - Emily Winks
- [3] YouTube: Fix Karpathy’s LLM Wiki with a Knowledge Graph | Claude Code + Obsidian + InfraNodus - Nodus Labs
Bildquelle: Google DALL-E 3 (04.2026).
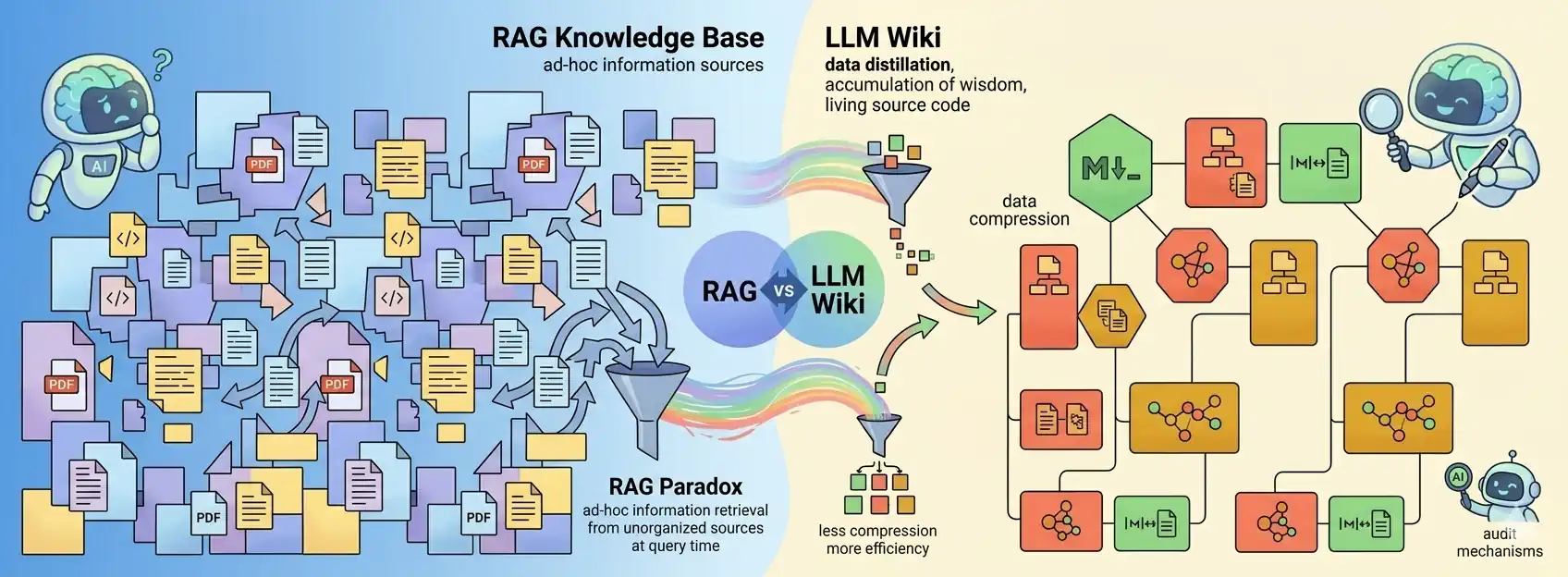
Potenzial und Vorteile von LLM Wiki
Das Konzept von LLM Wiki ist das Versprechen, dass unser Wissen aufhört, ein unüberwindbarer Haufen aus tausenden von Links zu sein. Es wird zu einer dynamischen Beschreibung relevanter Themen – eine „Wissenskapsel“, die Kerninformationen und deren Beziehungen untereinander enthält. Es ist ein Ort, an dem man wie durch ein Brennglas das Wesentliche fokussieren und verstreute Daten komfortabel verwalten kann. Hier ist, was diesen Ansatz für viele so faszinierend macht:
Durchbruch bei Effizienz und Kosten
- Extreme Kompression (Destillation): Das Versprechen einer 95-prozentigen Reduktion des Datenverbrauchs ist eine finanzielle Revolution.
Anstatt für das jedesmalige Senden von Fragmenten aus Rohdokumenten an das Modell zu bezahlen, zahlen Sie nur einmal für deren Destillation in kondensierte, saubere Markdown-Notizen.
Die vermeintlichen Mehrkosten durch das Einbetten des kompletten Wikis in den Kontext können mittels Prompt Caching erheblich gesenkt werden.
Wie der Autor selbst anmerkt [1]:
[Über RAG] „Das LLM entdeckt das Wissen bei jeder Frage neu. Es gibt keinen Kumulationseffekt.“
[Über LLM Wiki] „Wissen wird einmal kompiliert und dann aktualisiert, anstatt bei jeder Anfrage von Grund auf neu hergeleitet zu werden.“ - Höhere Antwortpräzision: Die Konzentration auf die „Essenz“ eliminiert das Informationsrauschen. Das Modell verliert sich nicht in langen Kontexten (der sogenannte Lost-in-the-Middle-Effekt), was zu treffsichereren Schlussfolgerungen führt.
- Blitzschnelle Antwortzeit: Ein kleinerer und saubererer Eingangskontext bedeutet, dass das Modell Antworten deutlich schneller generiert, was uns einer flüssigen Interaktion in Echtzeit näher bringt.
- Vereinfachter Tech-Stack: Der Wechsel von kostspieligen Vektordatenbanken und komplexen Servern zu einem einfachen Dateisystem macht das System kostengünstiger, wartungsfreundlicher und widerstandsfähiger gegen Ausfälle.
Neue Wissensqualität (KI als digitaler Bibliothekar)
- Kumulative Weisheit: Das Wissen im LLM Wiki „wächst“ und reift organisch. Erkenntnisse, die vor Monaten gewonnen wurden, verbinden sich automatisch mit neuen Daten, sodass das System mit jeder hinzugefügten Datei tatsächlich intelligenter wird.
- Widerspruchserkennung (Linting): Dies ist der Mechanismus der „Wissenskompilierung“. Die KI erkennt während des Audits Konflikte zwischen neuen Fakten und alten Notizen und zwingt uns zu entscheiden, was der Wahrheit entspricht und was ein Denkfehler ist.
- Automatische Standardisierung: Unabhängig davon, ob die Quelle ein chaotisches Transkript oder ein technisches PDF ist – LLM Wiki wandelt alles in ein konsistentes, strukturiertes Format um, das sowohl für die KI als auch für den Menschen leicht zu durchsuchen ist.
- Visualisierung der „Gedankentopologie“: Dank grafischer Beziehungsansichten (Graph View) sehen Sie die Landkarte Ihres Wissens. Dies ermöglicht es, nicht offensichtliche Brücken zwischen fernen Fachbereichen zu entdecken, die in losen Dateien unsichtbar bleiben.
Datensouveränität und Sicherheit
- Echte Eigenverantwortung (Human-Readable): Ihr Wissen besteht aus Textdateien auf Ihrer Festplatte. Selbst wenn KI-Anbieter verschwinden sollten, bleibt Ihre Datenbank bei Ihnen – sie bleibt über Jahrzehnte hinweg für Menschen und jeden einfachen Editor lesbar.
- Privatsphäre durch Lokalität: Die Möglichkeit, Audit- und Suchprozesse komplett offline (über lokale Modelle) durchzuführen, erlaubt die sichere Verarbeitung empfindlichster Firmengeheimnisse oder privater Gedanken.
- Transparenz und „Paper Trail“: Jede Behauptung im Wiki hat einen direkten Bezug zur Quelldatei im Ordner raw/. Dies reduziert Halluzinationen drastisch und ermöglicht es, in Sekundenschnelle zu prüfen, woher die KI eine bestimmte Schlussfolgerung gezogen hat.
Psychologische Entlastung und kognitiver Freiraum
- Schluss mit dem schlechten Gewissen (Anti-FOMO): Sie können hunderte interessante Artikel sammeln, ohne den Stress, sie nicht gelesen zu haben. Sie haben die Gewissheit, dass die KI sie „verdaut“ und Ihnen deren Essenz genau dann serviert, wenn Sie eine Frage zu diesem Thema stellen.
- Fokus auf Erschaffen statt Aufräumen: Die KI übernimmt die mühsame Rolle des Archivars – sie kümmert sich um Tags, Formatierung und interne Verlinkung. Sie bleiben der Architekt, der sich nur noch mit dem Stellen von Fragen und dem Verknüpfen von Fakten beschäftigt.
- Umsetzung des „Second Brain“-Versprechens: Dies ist die ultimative Erfüllung der Second Brain-Vision. Die Technologie beseitigt endlich die größte Barriere, die Nutzer bisher entmutigt hat: die Notwendigkeit der manuellen, mühsamen Ordnung der eigenen Notizen.
Nach Ansicht von Enthusiasten weist gerade das LLM Wiki die richtige Richtung für die Entwicklung persönlicher KI-Systeme. Anstatt riesige und schwerfällige „Datenspeicher“ zu bauen, setzen wir auf präzise „Wissensdestillerien“. Dies ist ein fundamentaler Paradigmenwechsel: der Übergang von roher quantitativer Verarbeitung hin zum Aufbau eines tiefen, strukturellen Verständnisses.
Herausforderungen und Grenzen von LLM Wiki
Obwohl die Vision von Andrej Karpathy äußerst verlockend klingt, bringt ihre Umsetzung eine Reihe einzigartiger Herausforderungen und technischer Einschränkungen mit sich. Da das LLM nicht mehr nur Leser ist, sondern zum aktiven Autor und Redakteur der Wissensdatenbank wird, steigen die Anforderungen an die Präzision und die Aufrechterhaltung der Systemkonsistenz erheblich. Es lohnt sich daher, die wichtigsten Schwierigkeiten und Barrieren zu analysieren, die dieses Muster mit sich bringt:
Architektur und Skalierungsbarrieren
- Engpass des Index: Dies ist ein entscheidendes Limit – das Anwachsen der Datei index.md kann das Kontextfenster des Modells überschreiten. Dies erzwingt die Erstellung von Subindizes, was die Systemarchitektur unnötig verkompliziert.
Wie der Autor selbst feststellte [1]:
„Dies funktioniert erstaunlich gut bei moderater Skalierung (ca. 100 Quellen, einige hundert Seiten)…“
- Verlustbehaftete Kompression (Detailverlust): Bei der Destillation von Inhalten in das Wiki-Format verliert die KI unweigerlich subtile Details. Wenn ein Benutzer auf eine ursprüngliche Nuance zugreifen möchte, erzwingt das System ohnehin die Rückkehr zu den Rohdateien, was den Sinn einer vollständigen Automatisierung in Frage stellt.
- Fehlende Transaktionssicherheit (Race Conditions): Markdown ist keine SQL-Datenbank. Wenn ein Agent und ein Mensch (oder zwei Agenten) gleichzeitig dieselbe Datei bearbeiten, riskieren wir eine „Konflikthölle“, Datenverlust oder Synchronisationsfehler. Dies ist eine enorme Barriere für die Teamarbeit.
- Fehlendes natives RBAC (Berechtigungen): In einem auf Textdateien basierenden System ist ein selektiver Zugriff schwer zu realisieren. Ein Agent muss in der Regel alles sehen, um Beziehungen aufzubauen, was den Verbleib von sensiblen und allgemeinen Daten in einer einzigen Datenbank ausschließt.
Wirtschaftlichkeit und Systemleistung
- Abhängigkeit von Modellen der „Schwergewichtsklasse“: LLM Wiki erfordert erstklassiges logisches Denken (z. B. die leistungsstärksten verfügbaren LLM-Modelle). Der Versuch, Audits oder Kompilierungen auf kleineren, lokalen Modellen auszuführen, endet meist in strukturellem Versagen und Verlinkungsfehlern.
- Hohe Betriebskosten: Die Verarbeitung einer einzigen neuen Information erfordert vom Modell zahlreiche Lese- und Schreiboperationen in verschiedenen Dateien. Dies ist wesentlich teurer und belastender für die API als die einfache Generierung eines Embeddings im klassischen RAG.
Laut Autor [1]:
„Die Verarbeitung einer einzigen Quelle kann die Bearbeitung von 10–15 Wiki-Seiten erfordern.“
- „Kompilierungssteuer“: Die erste Kompilierung einer großen Basis (z. B. 1000 Dokumente) kann eine gewaltige Rechnung verursachen und Stunden dauern. Es ist eine Investition, die sich mit der Zeit auszahlt, aber zu Beginn ein großes Budget und Geduld erfordert.
Risiko von Degradierung und Halluzinationen
- Semantische Drift (Stille Post): Wenn die KI eine Zusammenfassung zusammenfasst, kommt es mit der Zeit zu Vereinfachungen und der Akkumulation kleiner Fehler. Nach mehreren Aktualisierungszyklen könnte Ihr Wissen zu einer oberflächlichen Karikatur des Originals werden.
- Blindheit gegenüber Widersprüchen: Wenn eine widersprüchliche Information während des Audits nicht im aktuellen Kontextfenster landet, erkennt die KI sie möglicherweise nicht. Dies führt zur Entstehung „trüber“ und widersprüchlicher Artikel, die für das Modell zur neuen absoluten Wahrheit werden.
- Strukturelle Halluzinationen: Die KI liebt es, unzusammenhängende Konzepte „mit Gewalt“ zu verbinden oder fehlerhafte interne Links zu erstellen. Ohne harte Validierung (Linting) füllt sich die Basis schnell mit logischen „Monstern“, die schwer zu korrigieren sind.
Wartungsbarriere mit menschlicher Beteiligung (Human-in-the-loop)
- Hoher Überwachungsaufwand: Die Arbeitslast verlagert sich vom Schreiben hin zur mühsamen Überprüfung, ob der Bot die Dateistruktur nicht „durcheinandergebracht“ hat. Ohne aktives menschliches Engagement verwandelt sich das System schnell in einen digitalen Dachboden voller toter Links.
- „Prompt-Müdigkeit“: Das Erstellen von Anweisungen, die YAML-Formatierungen und Datenschemata streng überwachen, erfordert viele Tests und ständige Korrekturen nach Fehlern des Modells.
- Abhängigkeit von Drittanbieter-Tools: Wenn man ein System um spezifische Tools herum aufbaut (z. B. Obsidian + bestimmte Plugins), wird man zu deren Geisel. Jede Änderung in der Art und Weise, wie Markdown gerendert wird, kann einen schmerzhaften Umbau der gesamten Architektur erfordern.
Optimisten sind der Meinung, dass LLM Wiki derzeit der ehrgeizigste Versuch ist, das digitale Chaos zu ordnen. Obwohl diese Technologie Disziplin und hohe Anfangskosten erfordert, bietet sie etwas, das kein klassisches RAG bietet: eine lebendige, reifende Wissensstruktur anstelle eines toten Dateiarchivs. Letztendlich hängt der Erfolg dieses Ansatzes davon ab, ob wir die neue Rolle akzeptieren – nicht mehr nur als Datensammler, sondern als aktive Redakteure unserer eigenen Weisheit.
LLM Wiki Anwendungsfälle
Der Autor identifiziert fünf primäre Anwendungsfälle für das LLM-Wiki [1]:
- Persönliches Wissensmanagement (PKM): Zentralisierung vielfältiger Daten und Reflexionen, um langfristiges Wachstum zu verfolgen und ein strukturiertes digitales Porträt des eigenen Lebens zu erstellen.
- Forschung: Synthese der langfristigen Ansammlung komplexer Informationen, um eine sich entwickelnde These zu verfeinern und Unstimmigkeiten zwischen verschiedenen Quellen aufzuzeigen.
- Begleiter für Literatur & Medien („Ein Buch lesen“): Erstellung eines dynamischen, vernetzten Wikis, das Charaktere, Themen und narrative Zusammenhänge automatisch abbildet, während der Nutzer Inhalte konsumiert.
- Unternehmen & Teams: Pflege einer selbstaktualisierenden internen Wissensdatenbank, die fragmentierte Kommunikation (Slack, Meetings) in eine kohärente, stets aktuelle Ressource verwandelt.
- Wettbewerbsanalyse, Due Diligence, Reiseplanung, Kursnotizen, Hobby-Vertiefungen: Alles, bei dem Wissen über einen längeren Zeitraum angesammelt wird und das organisiert statt verstreut vorliegen soll.
Ich habe das Gefühl, dass noch viele weitere Anwendungsfälle für das LLM-Wiki auftauchen werden. Ich kann mir unzählige Szenarien vorstellen, in denen eine aktive Wissenssynthese ideal wäre – besonders dann, wenn die Menge der Dokumente (das vorhandene Wissen) noch relativ überschaubar ist. Zum Beispiel:
- Chatbot- oder Voicebot-POCs: Viele Unternehmen, die zum ersten Mal einen Chat- oder Voicebot implementieren, verfügen noch nicht über eine große Wissensdatenbank. Die Überführung vorhandener Informationen in ein Wiki ist ein wahrer Segen für alle, die hier ihre ersten Schritte machen. So werden lose, unstrukturierte Dokumente in ein verwaltbares und nützliches Format umgewandelt. Das Review und die Versionierung dieser Basis sind bei der Implementierung weiterer POC-Iterationen besonders wichtig.
- Sprachnotizen: Man kann kaum erwarten, dass eine Sammlung von Sprachnotizen von Natur aus eine tiefe Struktur besitzt. Sicher, eine Aufnahme hat ein Datum, und ein gewissenhafter Nutzer weist ihr vielleicht Themen oder Tags zu. Doch je mehr Notizen dazukommen, desto schwieriger wird es, Zusammenhänge oder spezifische Details zu finden, die über einfache Schlagworte hinausgehen. Der Einsatz eines LLM-Wikis weckt die Hoffnung, dass diese Notizen nicht nur leichter durchsuchbar, sondern auch analysierbar werden, sodass Widersprüche und Unstimmigkeiten effizient aufgespürt und gelöst werden können.
- Narrative & World-Building für Kreative: Autoren und Game Master kämpfen oft mit dem Problem der „Kontinuitätsdrift“. Wenn man einen Roman schreibt oder eine komplexe D&D-Kampagne leitet, kann das LLM sicherstellen, dass ein Verweis auf die Vergangenheit eines Charakters in einem späteren Kapitel automatisch einen Widerspruch meldet, falls diese dort anders beschrieben wurde als zu Beginn. Das System fungiert hier als Kontinuitäts-Editor.
- Mapping von technischer Schuld und Dokumentation: Quellcode ändert sich oft schneller als die zugehörige Dokumentation. Indem man ein LLM-Wiki mit Git-Commits und Pull-Request-Beschreibungen füttert, lässt sich ein High-Level-Wiki der „Systemarchitektur“ pflegen. Dies schließt die Lücke zwischen dem rohen Code (Quellen) und dem Verständnis der Entwickler (Wiki) und zeigt auf, wo neue Features mit der Legacy-Logik kollidieren könnten.
- Management von Rechts- oder Medizinfällen: Diese Bereiche bringen enorme Mengen an „Rohquellen“ mit sich (Patientenaktien, Gerichtsakten), bei denen die Datensynthese entscheidend ist. Ein LLM-Wiki könnte eine „Master-Timeline“ oder eine „Beweismittel-Zusammenfassung“ führen, die sich mit jedem neuen Dokument aktualisiert. Eine Linting-Funktion wäre hier unbezahlbar, um widersprüchliche Zeugenaussagen oder Lücken in der Krankengeschichte aufzudecken.
- Karriere-Register und Personal Branding: Über die Jahre vergisst man oft die eigenen Erfolge. Durch die Verarbeitung von Leistungsbeurteilungen, Projekt-Retrospektiven und E-Mails baut das LLM ein strukturiertes Wiki Ihrer Fähigkeiten und Erfolge auf, basierend auf der S.T.A.R.-Methode (Situation, Task, Action, Result). Wenn es Zeit für ein CV-Update oder ein Vorstellungsgespräch ist, liegt die fertige Synthese bereits vor.
Zusammenfassung des Duells: LLM-Wiki vs. RAG
Im Jahr 2026 ist RAG äußerst nützlich, weit verbreitet und optimiert. Es wird in vielen verschiedenen Varianten angeboten, und sein Ökosystem wächst stetig. RAG wird in Tausenden von Projekten produktiv eingesetzt; viele seiner Eigenschaften sind uns bereits bestens vertraut. Wir kennen auch seine Grenzen sowie die Probleme, für die wir wirksame Lösungsansätze zur Risikominderung entwickelt haben.
LLM Wiki ist (im Gegensatz zum klassischen RAG) eine Neuheit. Dieses Muster nutzt den RAG-Mechanismus „unter der Haube“, jedoch auf eine etwas andere Weise. Mit diesem Ansatz sind große Hoffnungen verbunden, und zweifellos könnte LLM Wiki im Zuge seiner Weiterentwicklung zu einer interessanten Alternative werden. LLM Wiki ist das richtige Werkzeug für mittelgroße Kontexte mit hoher Präzision, bei denen die Wissenssynthese wichtiger ist als die Größe der Datenbank. Es könnte jedoch in anderen Einsatzbereichen, in denen RAG seine Stärken voll ausspielt, wesentlich weniger effektiv sein.
Ich denke, es ist noch zu früh, um RAG-basierte Produktionssysteme auf LLM-Wikis umzustellen. Es lohnt sich jedoch, Experimente durchzuführen, um zu prüfen, inwieweit sich dieses neue Muster für ein bestimmtes Problem oder eine bestimmte Domäne eignet. Dies gilt insbesondere dann, wenn wir es mit einer sehr geringen Anzahl von Dokumenten in der Wissensdatenbank zu tun haben. Man sollte am Ball bleiben, da ich das Gefühl habe, dass uns eine interessante Entwicklung dieser Idee bevorsteht und neue Lösungen, die dem LLM-Wiki ähneln, sich als noch revolutionärer und nützlicher erweisen könnten.
Schreibe einen Kommentar
Empfohlene Beiträge

AI Tinkerers Gdańsk Meetup – 23. April
Sei dabei, wenn ich das Scaling von RAG Hybrid Search analysiere: Vom Konzept bis zu 780.000 Seiten