Hybrider RAG mit semantischem Chunking
Skalierung der RAG-Hybridsuche auf 780.000 Seiten
 Piotr Chlebek · 2026-4-(In Bearbeitung)
Piotr Chlebek · 2026-4-(In Bearbeitung)
Zusammenfassung: in progress..
Schlüsselwörter: in progress..
(In Bearbeitung)
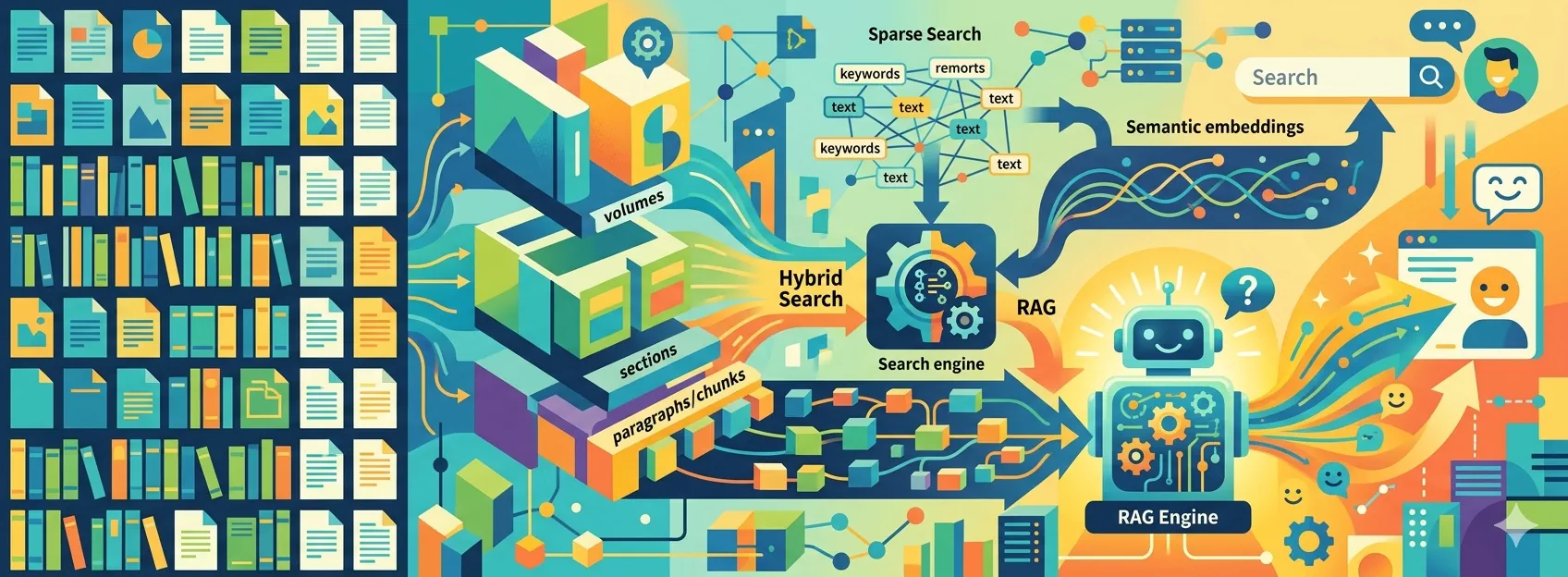
Architektur einer privaten, vertikalen Suchmaschine für eine Bibliothek mit 6.000 Dokumenten
Die Bibliothek, die ich mir immer gewünscht habe: schnell, lokal und unter Kontrolle
Dieses Projekt entstand aus meiner Leidenschaft für Sachbücher und wissensintensive Branchenartikel. Schon lange habe ich davon geträumt, ein System zu bauen, das meine große Sammlung an Dokumenten zu Themen, die mir wichtig sind, „verstehen“ und verarbeiten kann.
Dieser Text ist aus einer Kombination von drei Impulsen entstanden. Erstens wollte ich die Themen vertiefen, für die während meiner Präsentation: AI Tinkerers Gdańsk Meetup – 23. April. Zweitens macht mir das Schreiben einfach Spaß und ist der beste Weg, meine Gedanken zu ordnen. Der wichtigste Anstoß waren jedoch meine Branchenkollegen – ihr Zuspruch und ihre Neugier auf meine Erfahrungen mit neuen Technologien haben mich schließlich dazu bewegt, in die Tasten zu hauen. Da sie der Meinung waren, dass diese Erfahrungen es wert sind, geteilt zu werden, wollte ich sie nicht enttäuschen.
Das 5-Millionen-Prompt-Problem
Nach der Verarbeitung von ca. 6.000 PDFs kam ich auf 780.000 Seiten. Da ich für jede Seite mehrere Prompts zur Metadaten-Extraktion verwendet habe, mussten insgesamt etwa 5 Millionen LLM-Anfragen verarbeitet werden.
Die Verarbeitung von 5 Millionen Prompts in der Cloud ist teuer. Selbst mit modernen Funktionen wie Prompt-Caching oder günstigeren Batch-Preisen sind die Kosten immer noch zu hoch. Um Geld zu sparen, habe ich mich stattdessen für meine eigene lokale Hardware entschieden. Ein großer Bonus: Die lokale Ausführung garantiert die volle Privatsphäre meiner Daten. Wie ich das mit vLLM umgesetzt habe, erfährst du hier: Lokales Serving des LLM mit vLLM.
Natürlich gibt es auch Herausforderungen. Lokale KI hat in der Regel eine höhere Latenz (langsamere Antwortzeiten) als große Cloud-Anbieter. Deshalb muss ich vorsichtig sein, wie ich LLMs für bestimmte Echtzeit-Aufgaben einsetze, wie zum Beispiel das Reranking von Suchergebnissen.
In diesem Beitrag:
- (In Bearbeitung)
Ähnliche Beiträge:
- AI Tinkerers Gdańsk Meetup – 23. April
- Bei RAG geht es nicht um KI, sondern um Engineering
- LLM-Wiki vs. RAG-Wissensdatenbank
- Lokales Serving des LLM mit vLLM
Referenzen:
- [.] karpathy/llm-wiki.md - Andrej Karpathy
- [.] -
Bildquelle: Google DALL-E 3 (04.2026).