Lokales Serving des LLM mit vLLM
Aufbau einer kosteneffizienten KI-Infrastruktur: Lokales LLM-Serving via vLLM
 Piotr Chlebek · 2026-4-(In Bearbeitung)
Piotr Chlebek · 2026-4-(In Bearbeitung)
Zusammenfassung: in progress..
Schlüsselwörter: in progress..
(In Bearbeitung)
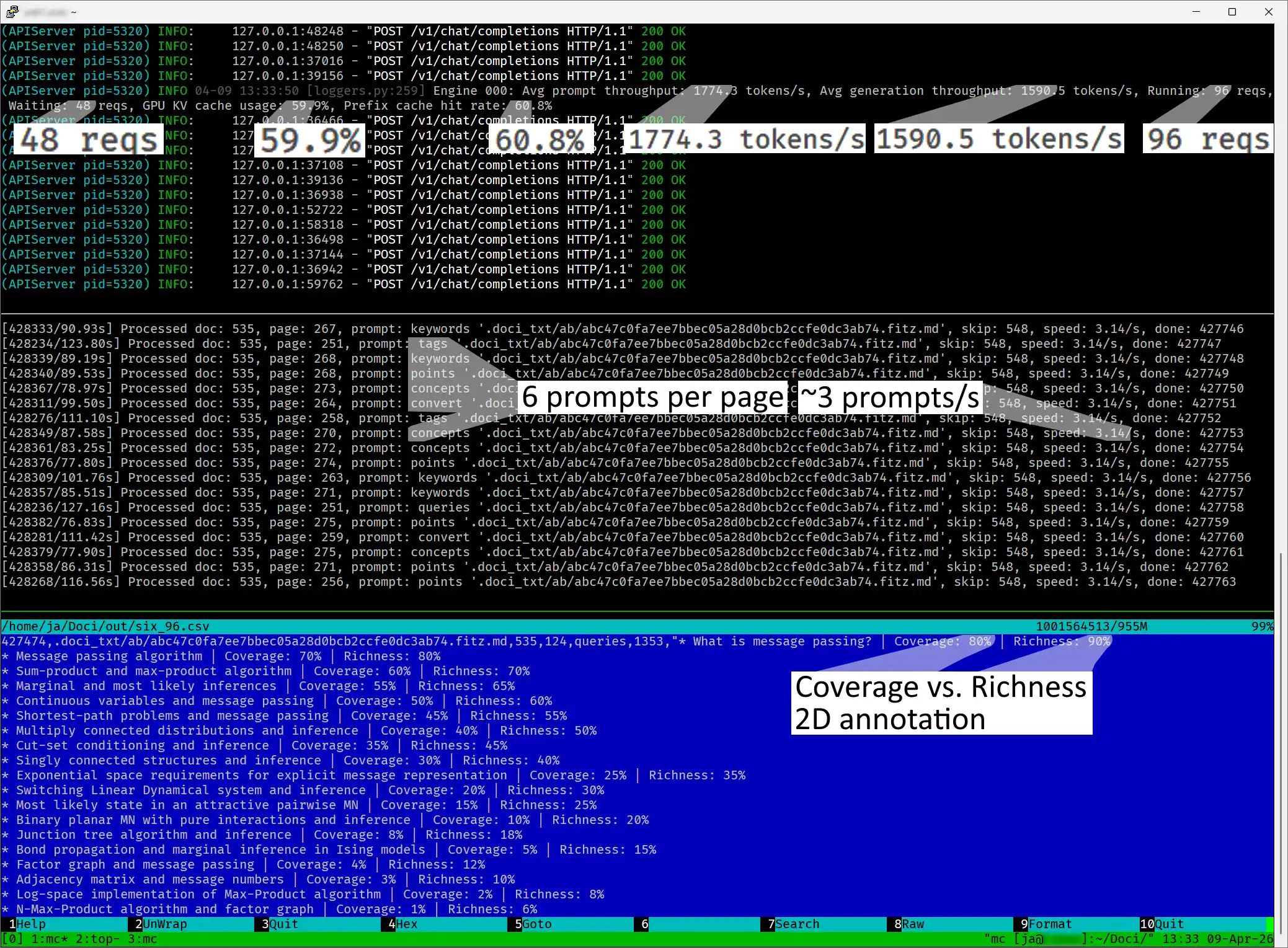
Wie man 5,46 Millionen LLM-Prompts ohne „API-Steuer“ verarbeitet
Das 5-Millionen-Prompt-Problem
Im Rahmen meines Projekts Hybrider RAG mit semantischem Chunking stand ich vor einer riesigen Herausforderung: der Analyse von 780.000 Dokumentenseiten. Mein Ziel war es, ein LLM zu nutzen, um Metadaten zu extrahieren und so die Informationssuche zu verbessern. Die Mathematik dahinter war gnadenlos – da jede Seite mehrere Prompts benötigte, wuchs das Projekt auf insgesamt 5 Millionen LLM-Anfragen an.
Warum vLLM?
Für meinen speziellen Anwendungsfall ist der Durchsatz (wie viele Aufgaben pro Stunde abgeschlossen werden) der wichtigste Wert, nicht die Latenz (wie schnell eine einzelne Aufgabe abgeschlossen wird). Nachdem ich verschiedene Meinungen im Internet recherchiert hatte, entschied ich mich für vLLM.
Es ist wichtig zu erwähnen, dass es viele andere Frameworks gibt – einige davon habe ich am Rand dieses Artikels aufgelistet. Ein Vergleich all dieser Tools würde den Rahmen dieses Projekts sprengen, wäre aber ein hervorragendes Thema für einen zukünftigen Artikel.
Hardware
Optimierungen
Modelle
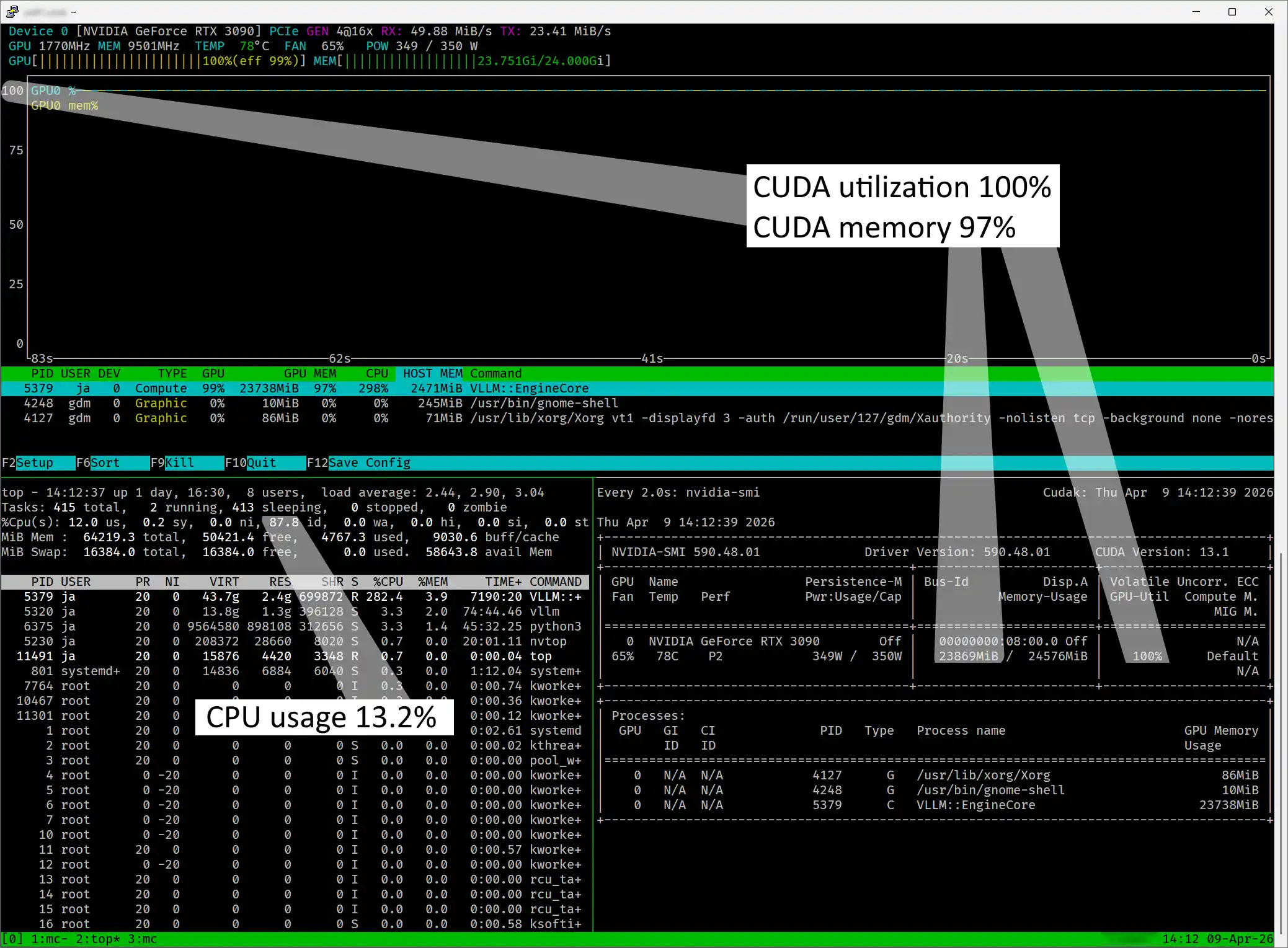
Überwachung
Schlussfolgerungen
...In diesem Beitrag:
- (In Bearbeitung)
Ähnliche Beiträge:
- AI Tinkerers Gdańsk Meetup – 23. April
- Bei RAG geht es nicht um KI, sondern um Engineering
- LLM-Wiki vs. RAG-Wissensdatenbank
- Hybrider RAG mit semantischem Chunking
Optionen für das LLM-Serving
- vLLM – Eine Engine mit hohem Durchsatz, entwickelt für maximale Speichereffizienz.
- NVIDIA Triton – Eine Enterprise-Lösung, konzipiert für hochperformante Skalierung.
- SGLang – Ein schnelles Framework für Sprach- und multimodale Modelle.
- LMDeploy – Ein spezialisiertes Toolkit zur Komprimierung und Bereitstellung effizienter Modelle.
- TensorRT-LLM – NVIDIAs offizielle Bibliothek für modernste GPU-Optimierungen.
- TGI – Das Toolkit von Hugging Face für zuverlässiges, produktionsreifes LLM-Serving.
- Ollama – Der einfachste und beliebteste Weg, offene Modelle lokal auszuführen.
- LM Studio – Eine benutzerfreundliche Desktop-App für private, lokale KI-Experimente.
- LocalAI – Eine All-in-One-Lokal-Alternative zu bekannten Cloud-KI-APIs.
- Ray Serve – Ein flexibles System für den Aufbau skalierbarer und programmierbarer KI-Dienste.
- llama.cpp – Eine schlanke C/C++ Basis für schnelle Inferenz auf jeder Hardware.
Referenzen:
- (In Bearbeitung)
Bildquelle: Google DALL-E 3 (04.2026).