Hybrid RAG with Semantic Chunking
Scaling RAG Hybrid Search on 780K Pages
 Piotr Chlebek · 2026-4-(work in progress)
Piotr Chlebek · 2026-4-(work in progress)
Abstract: in progress..
Keywords: in progress..
(work in progress)
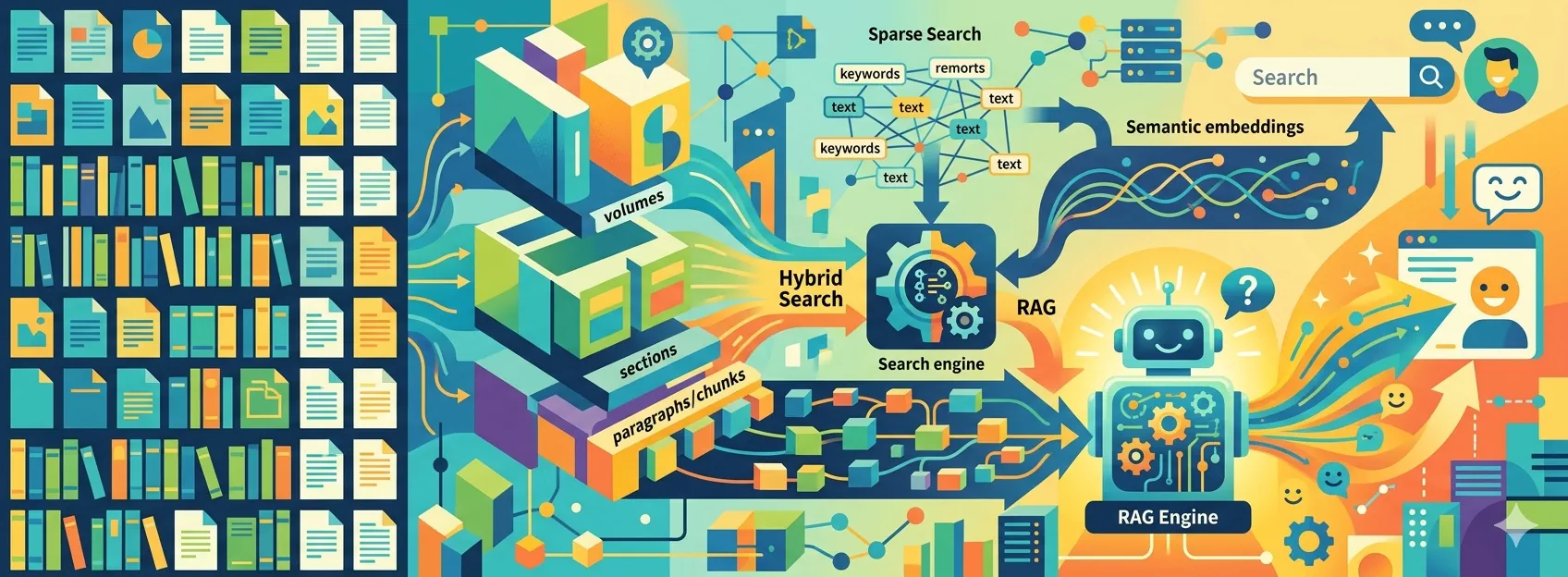
Architecting a Private, Vertical Search Engine for a Library of 6,000 Documents
The Library I Always Wanted: Fast, Local, and Under Control
This project was born from my love for non-fiction books and knowledge-dense industry articles. For a long time, I dreamed of building a system that could "understand" and process my large collection of documents on topics I care about.
This text was born from a mix of three sparks. First, I wanted to expand on the ideas that there won't be enough time for during my presentation: AI Tinkerers Gdańsk Meetup – April 23rd. Second, writing is pure joy for me and the best way to organize my thoughts. But the most important catalyst was my colleagues in the industry – it was their encouragement and curiosity about my struggles with new technologies that finally got me to sit down at the keyboard. Since they felt these experiences were worth writing about, I couldn't let them down.
The 5 Million Prompts
After processing ~6k PDFs, I ended up with 780,000 pages. I decided to use several prompts to extract metadata from each page, so I ended up having about 5 million LLM queries to process.
Processing 5 million prompts in the cloud is not cheap. Even with modern features like prompt caching or batch pricing for slower results, the costs are still too high. To save money, I decided to use my own local hardware instead. As a major bonus, running everything locally ensures total privacy for my data. You can find out how I managed to do it with vLLM here: Serving the LLM locally with vLLM.
Of course, there are challenges. Local AI usually has higher latency (slower response times) than big cloud providers. Because of this, I have to be careful about how I use LLMs for certain real-time tasks, such as reranking search results.
In this post:
- (work in progress)
Related Posts:
- AI Tinkerers Gdańsk Meetup – April 23rd
- RAG isn't about AI; it's about engineering
- LLM Wiki vs. RAG Knowledge Base
- Serving the LLM locally with vLLM
References:
- [.] karpathy/llm-wiki.md - Andrej Karpathy
- [.] -
Images Source: Google DALL-E 3 (04.2026).