Serving the LLM locally with vLLM
Building Cost-Efficient AI Infrastructure: Local LLM Serving via vLLM
 Piotr Chlebek · 2026-4-(work in progress)
Piotr Chlebek · 2026-4-(work in progress)
Abstract: in progress..
Keywords: in progress..
(work in progress)
How to Run 5.46 Million LLM Prompts Without the "API Tax"
The 5-Million Prompt Problem
As part of my Hybrid RAG with Semantic Chunking project, I faced a massive challenge: analyzing 780,000 pages of documents. My goal was to use an LLM to extract metadata that would improve information retrieval. The math was simple but daunting—with several prompts needed for every page, the project grew to a scale of 5 million LLM queries.
Why vLLM?
For my specific use case, the most important metric is throughput (how many tasks are finished per hour), not latency (how quickly a single task is completed). After researching different opinions online, I decided to try vLLM.
It’s worth noting that there are many other serving frameworks available — I've listed a few on the side of this article. While comparing all of them is outside the scope of this current project, it would be a great topic for a future article.
Hardware
Optimizations
Models
Monitoring
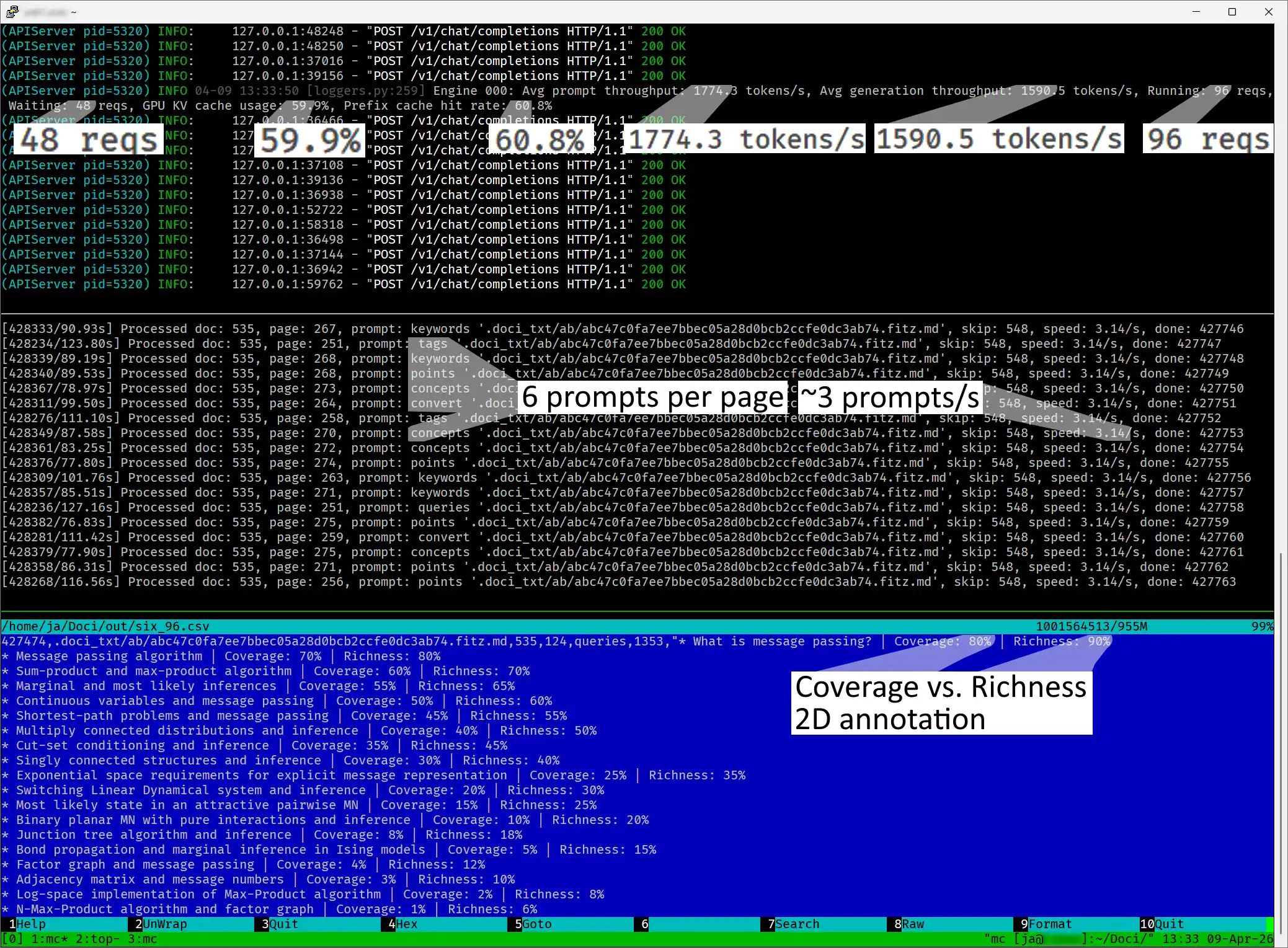
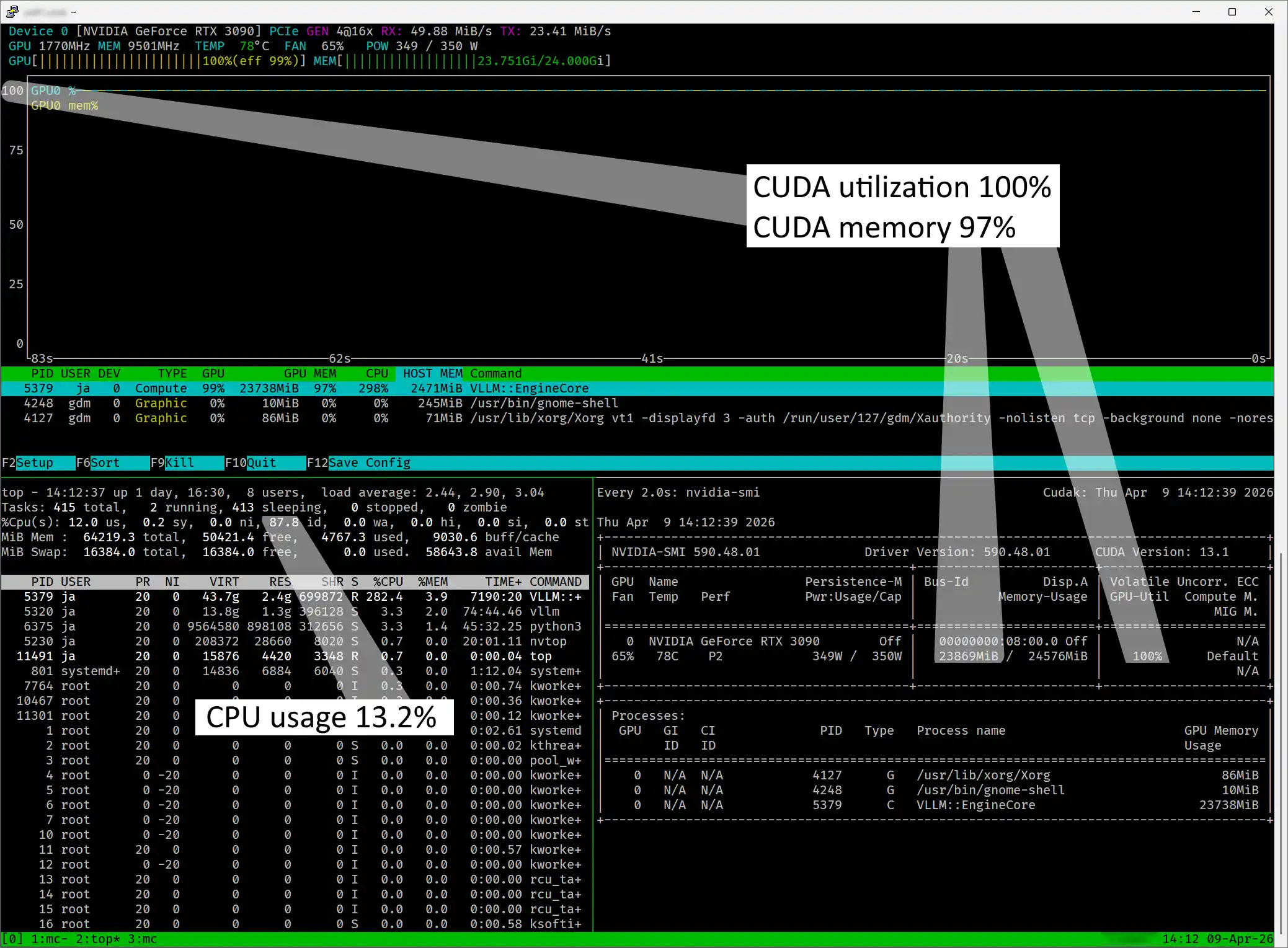
Conclusions
...In this post:
- (work in progress)
Related Posts:
- AI Tinkerers Gdańsk Meetup – April 23rd
- RAG isn't about AI; it's about engineering
- LLM Wiki vs. RAG Knowledge Base
- Hybrid RAG with Semantic Chunking
LLM Serving Options
- vLLM – A high-throughput engine designed for maximum memory efficiency.
- NVIDIA Triton – An enterprise-grade choice built for high-performance scaling.
- SGLang – A fast serving framework for both language and multimodal models.
- LMDeploy – A specialized toolkit for compressing and deploying efficient models.
- TensorRT-LLM – NVIDIA’s official library for state-of-the-art GPU optimizations.
- TGI – Hugging Face’s toolkit for reliable, production-ready LLM serving.
- Ollama – The simplest and most popular way to run open models locally.
- LM Studio – A user-friendly desktop app for private, local AI experimentation.
- LocalAI – An all-in-one, local alternative to popular cloud-based AI APIs.
- Ray Serve – A flexible system for building scalable and programmable AI services.
- llama.cpp – A lightweight C/C++ foundation for fast inference on any hardware.
References:
- (work in progress)
Images Source: Google DALL-E 3 (04.2026).